- 1. Enable two-finger scroll via Settings in Windows 10
- 2. OpenCV Ref
- 3. Extract faces from images
- 3.2.1. OpenCV Face Recognition
Enable two-finger scroll via Settings in Windows 10

OpenCV Ref
- OpenCV: Install OpenCV-Python in Ubuntu
- EXTRACTING FACES AND FACIAL FEATURES FROM COLOR IMAGES | International Journal of Pattern Recognition and Artificial Intelligence
- OpenCV Face Recognition - PyImageSearch
- Cropping Faces from Images using OpenCV - Python - GeeksforGeeks
- Extracting faces using OpenCV Face Detection Neural Network | by Karan Bhanot | Towards Data Science
Extract faces from images
Extracting faces using OpenCV Face Detection Neural Network
- Extracting faces using OpenCV Face Detection Neural Network | by Karan Bhanot | Towards Data Science
Photo by Maxim Dužij on Unsplash
Recently, I came across the website https://www.pyimagesearch.com/ which has some of the greatest tutorials on OpenCV. While reading through its numerous articles, I found that OpenCV has its own Face Detection Neural Network with really high accuracy.
So I decided to work on a project using this Neural Network from OpenCV and extract faces from images. Such a process would come handy whenever someone is working with faces and needs to extract them from a number of images.
The complete project is available as a GitHub repository. For this article, I’ve taken a picture from my Instagram account.

Image used for extracting face
Aim
The project has two essential elements:
- Box around faces: Show white boxes around all the faces recognised in the image. The Python file is _data_generator.py_
- Extracted faces: Extract faces from all images in a folder and save each face into a destination folder to create a handy dataset. The Python file is _face_extractor.py_

Face detection and extraction
First, let’s perform the common steps for the two parts, i.e. importing libraries, loading the face detection model, creating output directory, reading images and detecting faces.
Project
Import libraries
I import os to access various files in the directory. Then, cv2 will be used to work with images. numpy helps to easily work with multi-dimensional arrays.
Define paths and load model
The model’s prototxt and caffemodel is provided in the OpenCV repo itself. I used the same and placed them in the model_data directory in my project. prototxt file includes the text description of the network and caffemodel includes the weights. I read the two files and loaded my model using cv2.
Create directory
If the directory where the resultant images will get stored does not exist, I’ll create the directory. The output folder is updated_images.
When working with extracting faces, I’ll save the faces into the directory faces. If it is not present, I’ll create it.
Read images
I loop through all images inside the images folder. After extracting the extension, I check that the files are either of the type .png or .jpg and just operate with those files only.
Detect faces
Using cv2.imread, I read the image, and create a blob using cv2.dnn.blobFromImage. Then, I input this blob into the model and get back the detections from the page using model.forward().
The common steps are now complete. For the first task, I’ll plot white rectangles around faces and save them in updated_images directory. For the second task, I’ll save the extracted faces in faces directory.
1. Create boxes around faces
One by one, I iterate over all of the faces detected in the image and extract their start and end points. Then, I extract the confidence of detection. If the algorithm is more than 50% confident that the detection is a face, I show a rectangle around it.
Then, using cv2.imwrite, I save the image to the updated_images folder with the same name.

Image with white rectangle around face
2. Extracting faces
As described above, I iterate all faces, calculate the confidence of detection and if it is more than 50%, I extract the face. Notice the line frame = image[startY:endY, startX:endX]. It extracts the face from the image.
Then, I dump this new image into the faces folder with the name as face number, followed by _, and then the name of the file. If we extracted the first face from an image named sampleImage.png, the name of the face file will be 0_sampleImage.png. With each face, I increment the count and after complete execution, I print the count to the console.

Extracted face
Finally, the project is ready. You can feed in as many images as possible and generate datasets which can be used for further projects.
Conclusion
In this article, I discussed using OpenCV Face Detection Neural Network to detect faces in an image, label them with white rectangles and extract faces into separate images.
As always, I’d love to hear about your thoughts and suggestions.
OpenCV Face Recognition
by Adrian Rosebrock on September 24, 2018
Click here to download the source code to this post
Last updated on July 4, 2021.

In this tutorial, you will learn how to use OpenCV to perform face recognition. To build our face recognition system, we’ll first perform face detection, extract face embeddings from each face using deep learning, train a face recognition model on the embeddings, and then finally recognize faces in both images and video streams with OpenCV.
Today’s tutorial is also a special gift for my fiancée, Trisha (who is now officially my wife). Our wedding was over the weekend, and by the time you’re reading this blog post, we’ll be at the airport preparing to board our flight for the honeymoon.
To celebrate the occasion, and show her how much her support of myself, the PyImageSearch blog, and the PyImageSearch community means to me, I decided to use OpenCV to perform face recognition on a dataset of our faces.
You can swap in your own dataset of faces of course! All you need to do is follow my directory structure in insert your own face images.
As a bonus, I’ve also included how to label “unknown” faces that cannot be classified with sufficient confidence.
To learn how to perform OpenCV face recognition, just keep reading!
- Update July 2021: Added section on alternative face recognition methods to consider, including how siamese networks can be used for face recognition.
![]()
Looking for the source code to this post?
JUMP RIGHT TO THE DOWNLOADS SECTION
OpenCV Face Recognition
In today’s tutorial, you will learn how to perform face recognition using the OpenCV library.
You might be wondering how this tutorial is different from the one I wrote a few months back on face recognition with dlib?
Well, keep in mind that the dlib face recognition post relied on two important external libraries:
- dlib (obviously)
- face_recognition (which is an easy to use set of face recognition utilities that wraps around dlib)
While we used OpenCV to facilitate face recognition, OpenCV itself was not responsible for identifying faces.
In today’s tutorial, we’ll learn how we can apply deep learning and OpenCV together (with no other libraries other than scikit-learn) to:
- Detect faces
- Compute 128-d face embeddings to quantify a face
- Train a Support Vector Machine (SVM) on top of the embeddings
- Recognize faces in images and video streams
All of these tasks will be accomplished with OpenCV, enabling us to obtain a “pure” OpenCV face recognition pipeline.
How OpenCV’s face recognition works
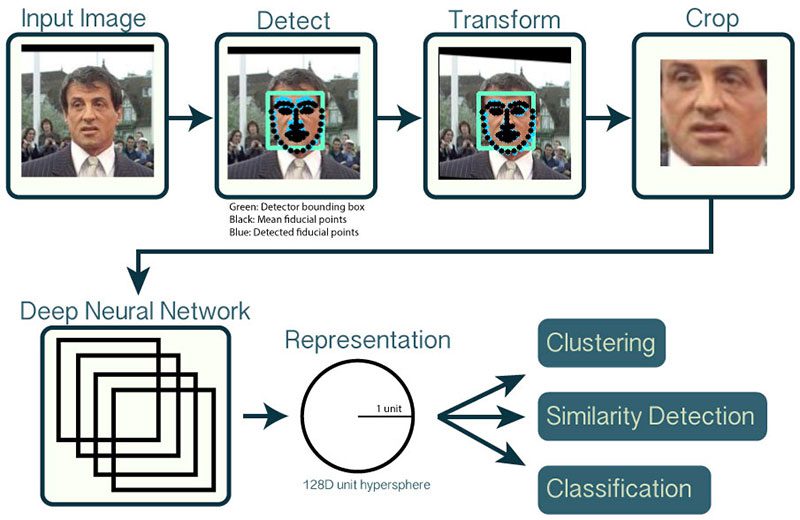
Figure 1: An overview of the OpenCV face recognition pipeline. The key step is a CNN feature extractor that generates 128-d facial embeddings. (source)
In order to build our OpenCV face recognition pipeline, we’ll be applying deep learning in two key steps:
- To apply face detection, which detects the presence and location of a face in an image, but does not identify it
- To extract the 128-d feature vectors (called “embeddings”) that quantify each face in an image
I’ve discussed how OpenCV’s face detection works previously, so please refer to it if you have not detected faces before.
The model responsible for actually quantifying each face in an image is from the OpenFace project, a Python and Torch implementation of face recognition with deep learning. This implementation comes from Schroff et al.’s 2015 CVPR publication, FaceNet: A Unified Embedding for Face Recognition and Clustering.
Reviewing the entire FaceNet implementation is outside the scope of this tutorial, but the gist of the pipeline can be seen in Figure 1 above.
First, we input an image or video frame to our face recognition pipeline. Given the input image, we apply face detection to detect the location of a face in the image.
Optionally we can compute facial landmarks, enabling us to preprocess and align the face.
Face alignment, as the name suggests, is the process of (1) identifying the geometric structure of the faces and (2) attempting to obtain a canonical alignment of the face based on translation, rotation, and scale.
While optional, face alignment has been demonstrated to increase face recognition accuracy in some pipelines.
After we’ve (optionally) applied face alignment and cropping, we pass the input face through our deep neural network:
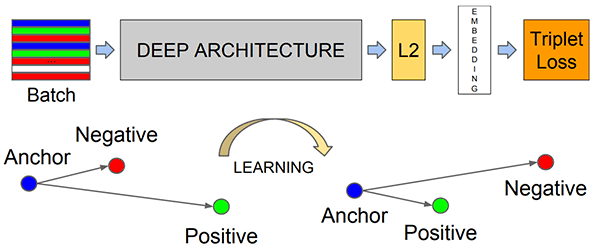
Figure 2: How the deep learning face recognition model computes the face embedding.
The FaceNet deep learning model computes a 128-d embedding that quantifies the face itself.
But how does the network actually compute the face embedding?
The answer lies in the training process itself, including:
- The input data to the network
- The triplet loss function
To train a face recognition model with deep learning, each input batch of data includes three images:
- The anchor
- The positive image
- The negative image
The anchor is our current face and has identity A.
The second image is our positive image — this image also contains a face of person A.
The negative image, on the other hand, does not have the same identity, and could belong to person B, C, or even Y!
The point is that the anchor and positive image both belong to the same person/face while the negative image does not contain the same face.
The neural network computes the 128-d embeddings for each face and then tweaks the weights of the network (via the triplet loss function) such that:
- The 128-d embeddings of the anchor and positive image lie closer together
- While at the same time, pushing the embeddings for the negative image father away
In this manner, the network is able to learn to quantify faces and return highly robust and discriminating embeddings suitable for face recognition.
And furthermore, we can actually reuse the OpenFace model for our own applications without having to explicitly train it!
Even though the deep learning model we’re using today has (very likely) never seen the faces we’re about to pass through it, the model will still be able to compute embeddings for each face — ideally, these face embeddings will be sufficiently different such that we can train a “standard” machine learning classifier (SVM, SGD classifier, Random Forest, etc.) on top of the face embeddings, and therefore obtain our OpenCV face recognition pipeline.
If you are interested in learning more about the details surrounding triplet loss and how it can be used to train a face embedding model, be sure to refer to my previous blog post as well as the Schroff et al. publication.
Our face recognition dataset

Figure 3: A small example face dataset for face recognition with OpenCV.
The dataset we are using today contains three people:
- Myself
- Trisha (my wife)
- “Unknown”, which is used to represent faces of people we do not know and wish to label as such (here I just sampled faces from the movie Jurassic Park which I used in a previous post — you may want to insert your own “unknown” dataset).
As I mentioned in the introduction to today’s face recognition post, I was just married over the weekend, so this post is a “gift” to my new wife ?.
Each class contains a total of six images.
If you are building your own face recognition dataset, ideally, I would suggest having 10-20 images per person you wish to recognize — be sure to refer to the “Drawbacks, limitations, and how to obtain higher face recognition accuracy” section of this blog post for more details.
Project structure
Once you’ve grabbed the zip from the “Downloads” section of this post, go ahead and unzip the archive and navigate into the directory.
From there, you may use the tree command to have the directory structure printed in your terminal:
$ tree –dirsfirst
.
├── dataset
│ ├── adrian [6 images]
│ ├── trisha [6 images]
│ └── unknown [6 images]
├── images
│ ├── adrian.jpg
│ ├── patrick_bateman.jpg
│ └── trisha_adrian.jpg
├── face_detection_model
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── output
│ ├── embeddings.pickle
│ ├── le.pickle
│ └── recognizer.pickle
├── extract_embeddings.py
├── openface_nn4.small2.v1.t7
├── train_model.py
├── recognize.py
└── recognize_video.py
7 directories, 31 files
There are quite a few moving parts for this project — take the time now to carefully read this section so you become familiar with all the files in today’s project.
Our project has four directories in the root folder:
-
dataset/: Contains our face images organized into subfolders by name. -
images/: Contains three test images that we’ll use to verify the operation of our model. -
face_detection_model/: Contains a pre-trained Caffe deep learning model provided by OpenCV to detect faces. This model detects and localizes faces in an image. output/: Contains my output pickle files. If you’re working with your own dataset, you can store your output files here as well. The output files include:-
embeddings.pickle: A serialized facial embeddings file. Embeddings have been computed for every face in the dataset and are stored in this file. -
le.pickle: Our label encoder. Contains the name labels for the people that our model can recognize. -
recognizer.pickle: Our Linear Support Vector Machine (SVM) model. This is a machine learning model rather than a deep learning model and it is responsible for actually recognizing faces.
-
Let’s summarize the five files in the root directory:
-
extract_embeddings.py: We’ll review this file in Step #1 which is responsible for using a deep learning feature extractor to generate a 128-D vector describing a face. All faces in our dataset will be passed through the neural network to generate embeddings. -
openface_nn4.small2.v1.t7: A Torch deep learning model which produces the 128-D facial embeddings. We’ll be using this deep learning model in Steps #1, #2, and #3 as well as the Bonus section. -
train_model.py: Our Linear SVM model will be trained by this script in Step #2. We’ll detect faces, extract embeddings, and fit our SVM model to the embeddings data. -
recognize.py: In Step #3 and we’ll recognize faces in images. We’ll detect faces, extract embeddings, and query our SVM model to determine who is in an image. We’ll draw boxes around faces and annotate each box with a name. -
recognize_video.py: Our Bonus section describes how to recognize who is in frames of a video stream just as we did in Step #3 on static images.
Let’s move on to the first step!
Step #1: Extract embeddings from face dataset
Now that we understand how face recognition works and reviewed our project structure, let’s get started building our OpenCV face recognition pipeline.
Open up the extract_embeddings.py file and insert the following code:
import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-i”, “–dataset”, required=True,
help=”path to input directory of faces + images”)
ap.add_argument(“-e”, “–embeddings”, required=True,
help=”path to output serialized db of facial embeddings”)
ap.add_argument(“-d”, “–detector”, required=True,
help=”path to OpenCV’s deep learning face detector”)
ap.add_argument(“-m”, “–embedding-model”, required=True,
help=”path to OpenCV’s deep learning face embedding model”)
ap.add_argument(“-c”, “–confidence”, type=float, default=0.5,
help=”minimum probability to filter weak detections”)
args = vars(ap.parse_args())
We import our required packages on Lines 2-8. You’ll need to have OpenCV and imutils installed. To install OpenCV, simply follow one of my guides (I recommend OpenCV 3.4.2, so be sure to download the right version while you follow along). My imutils package can be installed with pip:
$ pip install –upgrade imutils
Next, we process our command line arguments:
-
--dataset: The path to our input dataset of face images. -
--embeddings: The path to our output embeddings file. Our script will compute face embeddings which we’ll serialize to disk. -
--detector: Path to OpenCV’s Caffe-based deep learning face detector used to actually localize the faces in the images. -
--embedding-model: Path to the OpenCV deep learning Torch embedding model. This model will allow us to extract a 128-D facial embedding vector. -
--confidence: Optional threshold for filtering week face detections.
Now that we’ve imported our packages and parsed command line arguments, lets load the face detector and embedder from disk:
load our serialized face detector from disk
print(“[INFO] loading face detector…”)
protoPath = os.path.sep.join([args[“detector”], “deploy.prototxt”])
modelPath = os.path.sep.join([args[“detector”],
“res10_300x300_ssd_iter_140000.caffemodel”])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
load our serialized face embedding model from disk
print(“[INFO] loading face recognizer…”)
embedder = cv2.dnn.readNetFromTorch(args[“embedding_model”])
Here we load the face detector and embedder:
-
detector: Loaded via Lines 26-29. We’re using a Caffe based DL face detector to localize faces in an image. -
embedder: Loaded on Line 33. This model is Torch-based and is responsible for extracting facial embeddings via deep learning feature extraction.
Notice that we’re using the respective cv2.dnn functions to load the two separate models. The dnn module wasn’t made available like this until OpenCV 3.3, but I recommend that you are using OpenCV 3.4.2 or higher for this blog post.
Moving forward, let’s grab our image paths and perform initializations:
grab the paths to the input images in our dataset
print(“[INFO] quantifying faces…”)
imagePaths = list(paths.list_images(args[“dataset”]))
initialize our lists of extracted facial embeddings and
corresponding people names
knownEmbeddings = []
knownNames = []
initialize the total number of faces processed
total = 0
The imagePaths list, built on Line 37, contains the path to each image in the dataset. I’ve made this easy via my imutils function, paths.list_images .
Our embeddings and corresponding names will be held in two lists: knownEmbeddings and knownNames (Lines 41 and 42).
We’ll also be keeping track of how many faces we’ve processed via a variable called total (Line 45).
Let’s begin looping over the image paths — this loop will be responsible for extracting embeddings from faces found in each image:
loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
## extract the person name from the image path
print(“[INFO] processing image {}/{}”.format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
## load the image, resize it to have a width of 600 pixels (while
## maintaining the aspect ratio), and then grab the image
## dimensions
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]We begin looping over imagePaths on Line 48.
First, we extract the name of the person from the path (Line 52). To explain how this works, consider the following example in my Python shell:
$ python
from imutils import paths
import os
imagePaths = list(paths.list_images(“dataset”))
imagePath = imagePaths[0]
imagePath
‘dataset/adrian/00004.jpg’
imagePath.split(os.path.sep)
[‘dataset’, ‘adrian’, ‘00004.jpg’]
imagePath.split(os.path.sep)[-2]
‘adrian’
Notice how by using imagePath.split and providing the split character (the OS path separator — “/” on unix and “\” on Windows), the function produces a list of folder/file names (strings) which walk down the directory tree. We grab the second-to-last index, the persons name , which in this case is 'adrian' .
Finally, we wrap up the above code block by loading the image and resize it to a known width (Lines 57 and 58).
Let’s detect and localize faces:
## construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(image, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
## apply OpenCV's deep learning-based face detector to localize
## faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()On Lines 62-64, we construct a blob. To learn more about this process, please read Deep learning: How OpenCV’s blobFromImage works.
From there we detect faces in the image by passing the imageBlob through the detector network (Lines 68 and 69).
Let’s process the detections :
## ensure at least one face was found
if len(detections) > 0:
## we're making the assumption that each image has only ONE
## face, so find the bounding box with the largest probability
i = np.argmax(detections[0, 0, :, 2])
confidence = detections[0, 0, i, 2]
## ensure that the detection with the largest probability also
## means our minimum probability test (thus helping filter out
## weak detections)
if confidence > args["confidence"]:
## compute the (x, y)-coordinates of the bounding box for
## the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
## extract the face ROI and grab the ROI dimensions
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
## ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continueThe detections list contains probabilities and coordinates to localize faces in an image.
Assuming we have at least one detection, we’ll proceed into the body of the if-statement (Line 72).
We make the assumption that there is only one face in the image, so we extract the detection with the highest confidence and check to make sure that the confidence meets the minimum probability threshold used to filter out weak detections (Lines 75-81).
Assuming we’ve met that threshold, we extract the face ROI and grab/check dimensions to make sure the face ROI is sufficiently large (Lines 84-93).
From there, we’ll take advantage of our embedder CNN and extract the face embeddings:
## construct a blob for the face ROI, then pass the blob
## through our face embedding model to obtain the 128-d
## quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
## add the name of the person + corresponding face
## embedding to their respective lists
knownNames.append(name)
knownEmbeddings.append(vec.flatten())
total += 1We construct another blob, this time from the face ROI (not the whole image as we did before) on Lines 98 and 99.
Subsequently, we pass the faceBlob through the embedder CNN (Lines 100 and 101). This generates a 128-D vector (vec ) which describes the face. We’ll leverage this data to recognize new faces via machine learning.
And then we simply add the name and embedding vec to knownNames and knownEmbeddings , respectively (Lines 105 and 106).
We also can’t forget about the variable we set to track the total number of faces either — we go ahead and increment the value on Line 107.
We continue this process of looping over images, detecting faces, and extracting face embeddings for each and every image in our dataset.
All that’s left when the loop finishes is to dump the data to disk:
dump the facial embeddings + names to disk
print(“[INFO] serializing {} encodings…”.format(total))
data = {“embeddings”: knownEmbeddings, “names”: knownNames}
f = open(args[“embeddings”], “wb”)
f.write(pickle.dumps(data))
f.close()
We add the name and embedding data to a dictionary and then serialize the data in a pickle file on Lines 110-114.
At this point we’re ready to extract embeddings by running our script.
To follow along with this face recognition tutorial, use the “Downloads” section of the post to download the source code, OpenCV models, and example face recognition dataset.
From there, open up a terminal and execute the following command to compute the face embeddings with OpenCV:
$ python extract_embeddings.py –dataset dataset
–embeddings output/embeddings.pickle
–detector face_detection_model
–embedding-model openface_nn4.small2.v1.t7
[INFO] loading face detector…
[INFO] loading face recognizer…
[INFO] quantifying faces…
[INFO] processing image 1/18
[INFO] processing image 2/18
[INFO] processing image 3/18
[INFO] processing image 4/18
[INFO] processing image 5/18
[INFO] processing image 6/18
[INFO] processing image 7/18
[INFO] processing image 8/18
[INFO] processing image 9/18
[INFO] processing image 10/18
[INFO] processing image 11/18
[INFO] processing image 12/18
[INFO] processing image 13/18
[INFO] processing image 14/18
[INFO] processing image 15/18
[INFO] processing image 16/18
[INFO] processing image 17/18
[INFO] processing image 18/18
[INFO] serializing 18 encodings…
Here you can see that we have extracted 18 face embeddings, one for each of the images (6 per class) in our input face dataset.
Step #2: Train face recognition model
At this point we have extracted 128-d embeddings for each face — but how do we actually recognize a person based on these embeddings? The answer is that we need to train a “standard” machine learning model (such as an SVM, k-NN classifier, Random Forest, etc.) on top of the embeddings.
In my previous face recognition tutorial we discovered how a modified version of k-NN can be used for face recognition on 128-d embeddings created via the dlib and face_recognition libraries.
Today, I want to share how we can build a more powerful classifier on top of the embeddings — you’ll be able to use this same method in your dlib-based face recognition pipelines as well if you are so inclined.
Open up the train_model.py file and insert the following code:
import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
import argparse
import pickle
construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-e”, “–embeddings”, required=True,
help=”path to serialized db of facial embeddings”)
ap.add_argument(“-r”, “–recognizer”, required=True,
help=”path to output model trained to recognize faces”)
ap.add_argument(“-l”, “–le”, required=True,
help=”path to output label encoder”)
args = vars(ap.parse_args())
We’ll need scikit-learn, a machine learning library, installed in our environment prior to running this script. You can install it via pip:
$ pip install scikit-learn
We import our packages and modules on Lines 2-5. We’ll be using scikit-learn’s implementation of Support Vector Machines (SVM), a common machine learning model.
From there we parse our command line arguments:
-
--embeddings: The path to the serialized embeddings (we exported it by running the previousextract_embeddings.pyscript). -
--recognizer: This will be our output model that recognizes faces. It is based on SVM. We’ll be saving it so we can use it in the next two recognition scripts. -
--le: Our label encoder output file path. We’ll serialize our label encoder to disk so that we can use it and the recognizer model in our image/video face recognition scripts.
Each of these arguments is required.
Let’s load our facial embeddings and encode our labels:
load the face embeddings
print(“[INFO] loading face embeddings…”)
data = pickle.loads(open(args[“embeddings”], “rb”).read())
encode the labels
print(“[INFO] encoding labels…”)
le = LabelEncoder()
labels = le.fit_transform(data[“names”])
Here we load our embeddings from Step #1 on Line 19. We won’t be generating any embeddings in this model training script — we’ll use the embeddings previously generated and serialized.
Then we initialize our scikit-learn LabelEncoder and encode our name labels (Lines 23 and 24).
Now it’s time to train our SVM model for recognizing faces:
train the model used to accept the 128-d embeddings of the face and
then produce the actual face recognition
print(“[INFO] training model…”)
recognizer = SVC(C=1.0, kernel=”linear”, probability=True)
recognizer.fit(data[“embeddings”], labels)
On Line 29 we initialize our SVM model, and on Line 30 we fit the model (also known as “training the model”).
Here we are using a Linear Support Vector Machine (SVM) but you can try experimenting with other machine learning models if you so wish.
After training the model we output the model and label encoder to disk as pickle files.
write the actual face recognition model to disk
f = open(args[“recognizer”], “wb”)
f.write(pickle.dumps(recognizer))
f.close()
write the label encoder to disk
f = open(args[“le”], “wb”)
f.write(pickle.dumps(le))
f.close()
We write two pickle files to disk in this block — the face recognizer model and the label encoder.
At this point, be sure you executed the code from Step #1 first. You can grab the zip containing the code and data from the “Downloads” section.
Now that we have finished coding train_model.py as well, let’s apply it to our extracted face embeddings:
$ python train_model.py –embeddings output/embeddings.pickle
–recognizer output/recognizer.pickle
–le output/le.pickle
[INFO] loading face embeddings…
[INFO] encoding labels…
[INFO] training model…
$ ls output/
embeddings.pickle le.pickle recognizer.pickle
Here you can see that our SVM has been trained on the embeddings and both the (1) SVM itself and (2) the label encoding have been written to disk, enabling us to apply them to input images and video.
Step #3: Recognize faces with OpenCV
We are now ready to perform face recognition with OpenCV!
We’ll start with recognizing faces in images in this section and then move on to recognizing faces in video streams in the following section.
Open up the recognize.py file in your project and insert the following code:
import the necessary packages
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-i”, “–image”, required=True,
help=”path to input image”)
ap.add_argument(“-d”, “–detector”, required=True,
help=”path to OpenCV’s deep learning face detector”)
ap.add_argument(“-m”, “–embedding-model”, required=True,
help=”path to OpenCV’s deep learning face embedding model”)
ap.add_argument(“-r”, “–recognizer”, required=True,
help=”path to model trained to recognize faces”)
ap.add_argument(“-l”, “–le”, required=True,
help=”path to label encoder”)
ap.add_argument(“-c”, “–confidence”, type=float, default=0.5,
help=”minimum probability to filter weak detections”)
args = vars(ap.parse_args())
We import our required packages on Lines 2-7. At this point, you should have each of these packages installed.
Our six command line arguments are parsed on Lines 10-23:
-
--image: The path to the input image. We will attempt to recognize the faces in this image. -
--detector: The path to OpenCV’s deep learning face detector. We’ll use this model to detect where in the image the face ROIs are. -
--embedding-model: The path to OpenCV’s deep learning face embedding model. We’ll use this model to extract the 128-D face embedding from the face ROI — we’ll feed the data into the recognizer. -
--recognizer: The path to our recognizer model. We trained our SVM recognizer in Step #2. This is what will actually determine who a face is. -
--le: The path to our label encoder. This contains our face labels such as'adrian'or'trisha'. -
--confidence: The optional threshold to filter weak face detections.
Be sure to study these command line arguments — it is important to know the difference between the two deep learning models and the SVM model. If you find yourself confused later in this script, you should refer back to here.
Now that we’ve handled our imports and command line arguments, let’s load the three models from disk into memory:
load our serialized face detector from disk
print(“[INFO] loading face detector…”)
protoPath = os.path.sep.join([args[“detector”], “deploy.prototxt”])
modelPath = os.path.sep.join([args[“detector”],
“res10_300x300_ssd_iter_140000.caffemodel”])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
load our serialized face embedding model from disk
print(“[INFO] loading face recognizer…”)
embedder = cv2.dnn.readNetFromTorch(args[“embedding_model”])
load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args[“recognizer”], “rb”).read())
le = pickle.loads(open(args[“le”], “rb”).read())
We load three models in this block. At the risk of being redundant, I want to explicitly remind you of the differences among the models:
-
detector: A pre-trained Caffe DL model to detect where in the image the faces are (Lines 27-30). -
embedder: A pre-trained Torch DL model to calculate our 128-D face embeddings (Line 34). -
recognizer: Our Linear SVM face recognition model (Line 37). We trained this model in Step 2.
Both 1 & 2 are pre-trained meaning that they are provided to you as-is by OpenCV. They are buried in the OpenCV project on GitHub, but I’ve included them for your convenience in the “Downloads” section of today’s post. I’ve also numbered the models in the order that we’ll apply them to recognize faces with OpenCV.
We also load our label encoder which holds the names of the people our model can recognize (Line 38).
Now let’s load our image and detect faces:
load the image, resize it to have a width of 600 pixels (while
maintaining the aspect ratio), and then grab the image dimensions
image = cv2.imread(args[“image”])
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(image, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
apply OpenCV’s deep learning-based face detector to localize
faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
Here we:
- Load the image into memory and construct a blob (Lines 42-49). Learn about
cv2.dnn.blobFromImagehere. - Localize faces in the image via our
detector(Lines 53 and 54).
Given our new detections , let’s recognize faces in the image. But first we need to filter weak detections and extract the face ROI:
loop over the detections
for i in range(0, detections.shape[2]):
## extract the confidence (i.e., probability) associated with the
## prediction
confidence = detections[0, 0, i, 2]
## filter out weak detections
if confidence > args["confidence"]:
## compute the (x, y)-coordinates of the bounding box for the
## face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
## extract the face ROI
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
## ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continueYou’ll recognize this block from Step #1. I’ll explain it here once more:
- We loop over the
detectionson Line 57 and extract theconfidenceof each on Line 60. - Then we compare the
confidenceto the minimum probability detection threshold contained in our command lineargsdictionary, ensuring that the computed probability is larger than the minimum probability (Line 63). - From there, we extract the
faceROI (Lines 66-70) as well as ensure it’s spatial dimensions are sufficiently large (Lines 74 and 75).
Recognizing the name of the face ROI requires just a few steps:
## construct a blob for the face ROI, then pass the blob
## through our face embedding model to obtain the 128-d
## quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255, (96, 96),
(0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
## perform classification to recognize the face
preds = recognizer.predict_proba(vec)[0]
j = np.argmax(preds)
proba = preds[j]
name = le.classes_[j]First, we construct a faceBlob (from the face ROI) and pass it through the embedder to generate a 128-D vector which describes the face (Lines 80-83)
Then, we pass the vec through our SVM recognizer model (Line 86), the result of which is our predictions for who is in the face ROI.
We take the highest probability index (Line 87) and query our label encoder to find the name (Line 89). In between, I extract the probability on Line 88.
Note: You cam further filter out weak face recognitions by applying an additional threshold test on the probability. For example, inserting if proba < T (where T is a variable you define) can provide an additional layer of filtering to ensure there are less false-positive face recognitions.
Now, let’s display OpenCV face recognition results:
## draw the bounding box of the face along with the associated
## probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)show the output image
cv2.imshow(“Image”, image)
cv2.waitKey(0)
For every face we recognize in the loop (including the “unknown”) people:
- We construct a
textstring containing thenameand probability on Line 93. - And then we draw a rectangle around the face and place the text above the box (Lines 94-98).
And then finally we visualize the results on the screen until a key is pressed (Lines 101 and 102).
It is time to recognize faces in images with OpenCV!
To apply our OpenCV face recognition pipeline to my provided images (or your own dataset + test images), make sure you use the “Downloads” section of the blog post to download the code, trained models, and example images.
From there, open up a terminal and execute the following command:
$ python recognize.py –detector face_detection_model
–embedding-model openface_nn4.small2.v1.t7
–recognizer output/recognizer.pickle
–le output/le.pickle
–image images/adrian.jpg
[INFO] loading face detector…
[INFO] loading face recognizer…

Figure 4: OpenCV face recognition has recognized me at the Jurassic World: Fallen Kingdom movie showing.
Here you can see me sipping on a beer and sporting one of my favorite Jurassic Park shirts, along with a special Jurassic World pint glass and commemorative book. My face prediction only has 47.15% confidence; however, that confidence is higher than the “Unknown” class.
Let’s try another OpenCV face recognition example:
$ python recognize.py –detector face_detection_model
–embedding-model openface_nn4.small2.v1.t7
–recognizer output/recognizer.pickle
–le output/le.pickle
–image images/trisha_adrian.jpg
[INFO] loading face detector…
[INFO] loading face recognizer…
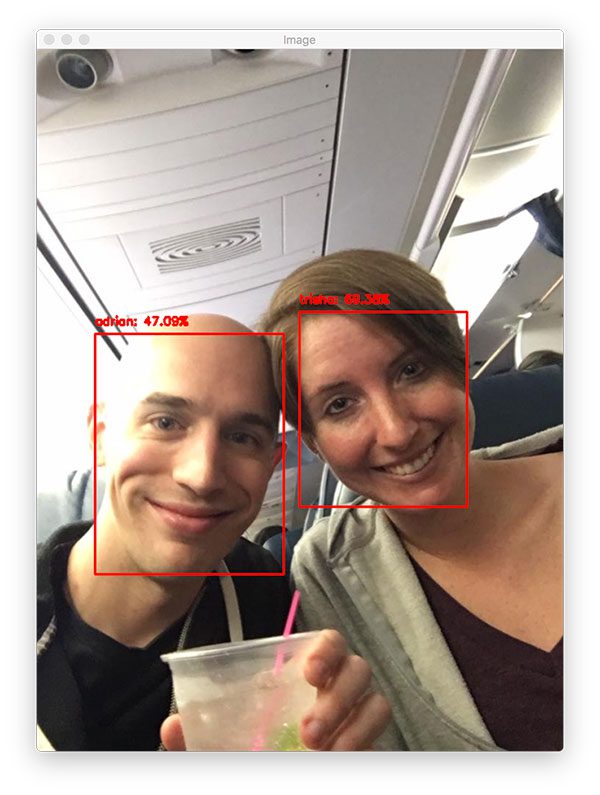
Figure 5: My wife, Trisha, and I are recognized in a selfie picture on an airplane with OpenCV + deep learning facial recognition.
Here are Trisha and I, ready to start our vacation!
In a final example, let’s look at what happens when our model is unable to recognize the actual face:
$ python recognize.py –detector face_detection_model
–embedding-model openface_nn4.small2.v1.t7
–recognizer output/recognizer.pickle
–le output/le.pickle
–image images/patrick_bateman.jpg
[INFO] loading face detector…
[INFO] loading face recognizer…

Figure 6: Facial recognition with OpenCV has determined that this person is “unknown”.
The third image is an example of an “unknown” person who is actually Patrick Bateman from American Psycho — believe me, this is not a person you would want to see show up in your images or video streams!
BONUS: Recognize faces in video streams
As a bonus, I decided to include a section dedicated to OpenCV face recognition in video streams!
The actual pipeline itself is near identical to recognizing faces in images, with only a few updates which we’ll review along the way.
Open up the recognize_video.py file and let’s get started:
import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import pickle
import time
import cv2
import os
construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-d”, “–detector”, required=True,
help=”path to OpenCV’s deep learning face detector”)
ap.add_argument(“-m”, “–embedding-model”, required=True,
help=”path to OpenCV’s deep learning face embedding model”)
ap.add_argument(“-r”, “–recognizer”, required=True,
help=”path to model trained to recognize faces”)
ap.add_argument(“-l”, “–le”, required=True,
help=”path to label encoder”)
ap.add_argument(“-c”, “–confidence”, type=float, default=0.5,
help=”minimum probability to filter weak detections”)
args = vars(ap.parse_args())
Our imports are the same as the Step #3 section above, except for Lines 2 and 3 where we use the imutils.video module. We’ll use VideoStream to capture frames from our camera and FPS to calculate frames per second statistics.
The command line arguments are also the same except we aren’t passing a path to a static image via the command line. Rather, we’ll grab a reference to our webcam and then process the video. Refer to Step #3 if you need to review the arguments.
Our three models and label encoder are loaded here:
load our serialized face detector from disk
print(“[INFO] loading face detector…”)
protoPath = os.path.sep.join([args[“detector”], “deploy.prototxt”])
modelPath = os.path.sep.join([args[“detector”],
“res10_300x300_ssd_iter_140000.caffemodel”])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
load our serialized face embedding model from disk
print(“[INFO] loading face recognizer…”)
embedder = cv2.dnn.readNetFromTorch(args[“embedding_model”])
load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args[“recognizer”], “rb”).read())
le = pickle.loads(open(args[“le”], “rb”).read())
Here we load face detector , face embedder model, face recognizer model (Linear SVM), and label encoder.
Again, be sure to refer to Step #3 if you are confused about the three models or label encoder.
Let’s initialize our video stream and begin processing frames:
initialize the video stream, then allow the camera sensor to warm up
print(“[INFO] starting video stream…”)
vs = VideoStream(src=0).start()
time.sleep(2.0)
start the FPS throughput estimator
fps = FPS().start()
loop over frames from the video file stream
while True:
## grab the frame from the threaded video stream
frame = vs.read()
## resize the frame to have a width of 600 pixels (while
## maintaining the aspect ratio), and then grab the image
## dimensions
frame = imutils.resize(frame, width=600)
(h, w) = frame.shape[:2]
## construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(frame, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
## apply OpenCV's deep learning-based face detector to localize
## faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()Our VideoStream object is initialized and started on Line 43. We wait for the camera sensor to warm up on Line 44.
We also initialize our frames per second counter (Line 47) and begin looping over frames on Line 50. We grab a frame from the webcam on Line 52.
From here everything is the same as Step 3. We resize the frame (L**ine 57**) and then we construct a blob from the frame + detect where the faces are (Lines 61-68).
Now let’s process the detections:
## loop over the detections
for i in range(0, detections.shape[2]):
## extract the confidence (i.e., probability) associated with
## the prediction
confidence = detections[0, 0, i, 2]
## filter out weak detections
if confidence > args["confidence"]:
## compute the (x, y)-coordinates of the bounding box for
## the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
## extract the face ROI
face = frame[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
## ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continueJust as in the previous section, we begin looping over detections and filter out weak ones (Lines 71-77). Then we extract the face ROI as well as ensure the spatial dimensions are sufficiently large enough for the next steps (Lines 84-89).
Now it’s time to perform OpenCV face recognition:
## construct a blob for the face ROI, then pass the blob
## through our face embedding model to obtain the 128-d
## quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
## perform classification to recognize the face
preds = recognizer.predict_proba(vec)[0]
j = np.argmax(preds)
proba = preds[j]
name = le.classes_[j]
## draw the bounding box of the face along with the
## associated probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
## update the FPS counter
fps.update()Here we:
- Construct the
faceBlob(Lines 94 and 95) and calculate the facial embeddings via deep learning (Lines 96 and 97). - Recognize the most-likely
nameof the face while calculating the probability (Line 100-103). - Draw a bounding box around the face and the person’s
name+ probability (Lines 107 -112).
Our fps counter is updated on Line 115.
Let’s display the results and clean up:
## show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
## if the `q` key was pressed, break from the loop
if key == ord("q"):
breakstop the timer and display FPS information
fps.stop()
print(“[INFO] elasped time: {:.2f}”.format(fps.elapsed()))
print(“[INFO] approx. FPS: {:.2f}”.format(fps.fps()))
do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
To close out the script, we:
- Display the annotated
frame(Line 118) and wait for the “q” key to be pressed at which point we break out of the loop (Lines 119-123). - Stop our
fpscounter and print statistics in the terminal (Lines 126-128). - Cleanup by closing windows and releasing pointers (Lines 131 and 132).
To execute our OpenCV face recognition pipeline on a video stream, open up a terminal and execute the following command:
$ python recognize_video.py –detector face_detection_model
–embedding-model openface_nn4.small2.v1.t7
–recognizer output/recognizer.pickle
–le output/le.pickle
[INFO] loading face detector…
[INFO] loading face recognizer…
[INFO] starting video stream…
[INFO] elasped time: 12.52
[INFO] approx. FPS: 16.13
Figure 7: Face recognition in video with OpenCV.
As you can see, both Trisha and my face are correctly identified! Our OpenCV face recognition pipeline is also obtaining ~16 FPS on my iMac. On my MacBook Pro I was getting ~14 FPS throughput rate.
Drawbacks, limitations, and how to obtain higher face recognition accuracy

Figure 8: All face recognition systems are error-prone. There will never be a 100% accurate face recognition system.
Inevitably, you’ll run into a situation where OpenCV does not recognize a face correctly.
What do you do in those situations?
And how do you improve your OpenCV face recognition accuracy? In this section, I’ll detail a few of the suggested methods to increase the accuracy of your face recognition pipeline
You may need more data

Figure 9: Most people aren’t training their OpenCV face recognition models with enough data. (image source)
My first suggestion is likely the most obvious one, but it’s worth sharing.
In my previous tutorial on face recognition, a handful of PyImageSearch readers asked why their face recognition accuracy was low and faces were being misclassified — the conversation went something like this (paraphrased):
Them: Hey Adrian, I am trying to perform face recognition on a dataset of my classmate’s faces, but the accuracy is really low. What can I do to increase face recognition accuracy?
Me: How many face images do you have per person?
Them: Only one or two.
Me: Gather more data.
I get the impression that most readers already know they need more face images when they only have one or two example faces per person, but I suspect they are hoping for me to pull a computer vision technique out of my bag of tips and tricks to solve the problem.
It doesn’t work like that.
If you find yourself with low face recognition accuracy and only have a few example faces per person, gather more data — there are no “computer vision tricks” that will save you from the data gathering process.
Invest in your data and you’ll have a better OpenCV face recognition pipeline. In general, I would recommend a minimum of 10-20 faces per person.
Note: You may be thinking, “But Adrian, you only gathered 6 images per person in today’s post!” Yes, you are right — and I did that to prove a point. The OpenCV face recognition system we discussed here today worked but can always be improved. There are times when smaller datasets will give you your desired results, and there’s nothing wrong with trying a small dataset — but when you don’t achieve your desired accuracy you’ll want to gather more data.
Perform face alignment

Figure 9: Performing face alignment for OpenCV facial recognition can dramatically improve face recognition performance.
The face recognition model OpenCV uses to compute the 128-d face embeddings comes from the OpenFace project.
The OpenFace model will perform better on faces that have been aligned.
Face alignment is the process of:
- Identifying the geometric structure of faces in images.
- Attempting to obtain a canonical alignment of the face based on translation, rotation, and scale.
As you can see from Figure 9 at the top of this section, I have:
- Detected a faces in the image and extracted the ROIs (based on the bounding box coordinates).
- Applied facial landmark detection to extract the coordinates of the eyes.
- Computed the centroid for each respective eye along with the midpoint between the eyes.
- And based on these points, applied an affine transform to resize the face to a fixed size and dimension.
If we apply face alignment to every face in our dataset, then in the output coordinate space, all faces should:
- Be centered in the image.
- Be rotated such the eyes lie on a horizontal line (i.e., the face is rotated such that the eyes lie along the same y-coordinates).
- Be scaled such that the size of the faces is approximately identical.
Applying face alignment to our OpenCV face recognition pipeline was outside the scope of today’s tutorial, but if you would like to further increase your face recognition accuracy using OpenCV and OpenFace, I would recommend you apply face alignment.
Check out my blog post, Face Alignment with OpenCV and Python.
Tune your hyperparameters
My second suggestion is for you to attempt to tune your hyperparameters on whatever machine learning model you are using (i.e., the model trained on top of the extracted face embeddings).
For this tutorial, we used a Linear SVM; however, we did not tune the C value, which is typically the most important value of an SVM to tune.
The C value is a “strictness” parameter and controls how much you want to avoid misclassifying each data point in the training set.
Larger values of C will be more strict and try harder to classify every input data point correctly, even at the risk of overfitting.
Smaller values of C will be more “soft”, allowing some misclassifications in the training data, but ideally generalizing better to testing data.
It’s interesting to note that according to one of the classification examples in the OpenFace GitHub, they actually recommend to not tune the hyperparameters, as, from their experience, they found that setting C=1 obtains satisfactory face recognition results in most settings.
Still, if your face recognition accuracy is not sufficient, it may be worth the extra effort and computational cost of tuning your hyperparameters via either a grid search or random search.
Use dlib’s embedding model (but not it’s k-NN for face recognition)
In my experience using both OpenCV’s face recognition model along with dlib’s face recognition model, I’ve found that dlib’s face embeddings are more discriminative, especially for smaller datasets.
Furthermore, I’ve found that dlib’s model is less dependent on:
- Preprocessing such as face alignment
- Using a more powerful machine learning model on top of extracted face embeddings
If you take a look at my original face recognition tutorial, you’ll notice that we utilized a simple k-NN algorithm for face recognition (with a small modification to throw out nearest neighbor votes whose distance was above a threshold).
The k-NN model worked extremely well, but as we know, more powerful machine learning models exist.
To improve accuracy further, you may want to use dlib’s embedding model, and then instead of applying k-NN, follow Step #2 from today’s post and train a more powerful classifier on the face embeddings.
Did you encounter a “USAGE” error running today’s Python face recognition scripts?
Each week I receive emails that (paraphrased) go something like this:
Hi Adrian, I can’t run the code from the blog post.
My error looks like this:
usage: extract_embeddings.py [-h] -i DATASET -e EMBEDDINGS
-d DETECTOR -m EMBEDDING_MODEL [-c CONFIDENCE]
extract_embeddings.py: error: the following arguments are required:
-i/–dataset, -e/–embeddings, -d/–detector, -m/–embedding-model
Or this:
I’m using Spyder IDE to run the code. It isn’t running as I encounter a “usage” message in the command box.
There are three separate Python scripts in this tutorial, and furthermore, each of them requires that you (correctly) supply the respective command line arguments.
If you’re new to command line arguments, that’s fine, but you need to read up on how Python, argparse, and command line arguments work before you try to run these scripts!
I’ll be honest with you — face recognition is an advanced technique. Command line arguments are a very beginner/novice concept. Make sure you walk before you run, otherwise you will trip up. Take the time now to educate yourself on how command line arguments.
Secondly, I always include the exact command you can copy and paste into your terminal or command line and run the script. You might want to modify the command line arguments to accommodate your own image or video data, but essentially I’ve done the work for you. With a knowledge of command line arguments you can update the arguments to point to your own data, without having to modify a single line of code.
For the readers that want to use an IDE like Spyder or PyCharm my recommendation is that you learn how to use command line arguments in the command line/terminal first. Program in the IDE, but use the command line to execute your scripts.
I also recommend that you don’t bother trying to configure your IDE for command line arguments until you understand how they work by typing them in first. In fact, you’ll probably learn to love the command line as it is faster than clicking through a GUI menu to input the arguments each time you want to change them. Once you have a good handle on how command line arguments work, you can then configure them separately in your IDE.
From a quick search through my inbox, I see that I’ve answered over 500-1,000 of command line argument-related questions. I’d estimate that I’d answered another 1,000+ such questions replying to comments on the blog.
Don’t let me discourage you from commenting on a post or emailing me for assistance — please do. But if you are new to programming, I urge you to read and try the concepts discussed in my command line arguments blog post as that will be the tutorial I’ll link you to if you need help.
Alternative OpenCV face recognition methods
In this tutorial, you learned how to perform face recognition using OpenCV and a pre-trained FaceNet model.
Unlike our previous tutorial on deep learning-based face recognition, which utilized two other libraries/packages (dlib and face_recognition), the method covered here today utilizes just OpenCV, therefore removing other dependencies.
However, it’s worth noting that there are other methods that you can utilize when creating your own face recognition systems.
I suggest starting with siamese networks. Siamese networks are specialized deep learning models that:
- Can be successfully trained with very little data
- Learn a similarity score between two images (i.e., how similar two faces are)
- Are the cornerstone of modern face recognition systems
I have an entire series of tutorials on siamese networks that I suggest you read to become familiar with them:
- Building image pairs for siamese networks with Python
- Siamese networks with Keras, TensorFlow, and Deep Learning
- Comparing images for similarity using siamese networks, Keras, and TensorFlow
- Contrastive Loss for Siamese Networks with Keras and TensorFlow
Additionally, there are non-deep learning-based face recognition methods you may want to consider:
- Face Recognition with Local Binary Patterns (LBPs) and OpenCV
- OpenCV Eigenfaces for Face Recognition
These methods are less accurate than their deep learning-based face recognition counterparts, but tend to be much more computationally efficient and will run faster on embedded systems.
What’s next? I recommend PyImageSearch University.
Course information:
30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you’re serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you’ll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
CLICK HERE TO JOIN PYIMAGESEARCH UNIVERSITY
Summary
In today’s blog post we used OpenCV to perform face recognition.
Our OpenCV face recognition pipeline was created using a four-stage process:
- Create your dataset of face images
- Extract face embeddings for each face in the image (again, using OpenCV)
- Train a model on top of the face embeddings
- Utilize OpenCV to recognize faces in images and video streams
Since I was married over this past weekend, I used photos of myself and Trisha (my now wife) to keep the tutorial fun and festive.
You can, of course, swap in your own face dataset provided you follow the directory structure of the project detailed above.
If you need help gathering your own face dataset, be sure to refer to this post on building a face recognition dataset.
I hope you enjoyed today’s tutorial on OpenCV face recognition!
To download the source code, models, and example dataset for this post (and be notified when future blog posts are published here on PyImageSearch), just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you’ll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!
DOWNLOAD THE CODE!

About the Author
Hi there, I’m Adrian Rosebrock, PhD. All too often I see developers, students, and researchers wasting their time, studying the wrong things, and generally struggling to get started with Computer Vision, Deep Learning, and OpenCV. I created this website to show you what I believe is the best possible way to get your start.
Reader Interactions
[
Previous Article:
pip install OpenCV
](https://pyimagesearch.com/2018/09/19/pip-install-opencv/)[
Next Article:
Install OpenCV 4 on your Raspberry Pi
](https://pyimagesearch.com/2018/09/26/install-opencv-4-on-your-raspberry-pi/)
359 responses to: OpenCV Face Recognition
Harald Vaessin
September 24, 2018 at 10:53 am
My heartfelt congratulations and best wishes for your future together.
And thank you for your wonderful tutorials!
HVJesudas
September 24, 2018 at 10:56 am
Congratulations Adrian on your marriage. Wishing you and Trisha the Very Best in Life !
Bhavesh kacha
Can we live stream that over a network??? If yes, then how ???
Adrian Rosebrock
You can follow this tutorial.
Tosho Futami
September 24, 2018 at 11:09 am
I am very appreciated for your weekly new code support. Conglaturation your marriage, please enjoy your forepufule future…
raj shah
hey can u help me to figure out this module (Opencv) ,i m getting an error i know its command line argument can u tell me the configuration parts of ur file.
-
September 24, 2018 at 11:22 am
Can this be used for detecting and recognising faces in a classroom with many students?
-
Hi Ayush, potentially it can be used for a classroom. There are several considerations to make:
- Due to the camera angle, some students’ faces may be obscured if the camera is positioned at the front of the classroom.
- Scaling of faces especially for low resolution cameras (depends on camera placement).
- Privacy concerns — especially since students/children are involved.
Huseyn
What is the maximum number of people i can trai and this system will work accurately?
-
falahgs
September 24, 2018 at 11:38 am
congratulations Adrian ..
i like all you are posts in geat blog
u really great prof.
thanks for this postNika
September 24, 2018 at 12:06 pm
Congratulations Adrian and thanks for the tutorial!
-
September 24, 2018 at 12:17 pm
Congratulations Adrian
happy Days Jesus Hdz Soberon
Congratulations Adrian for you and now for your wife. My best wishes in this new stage of your lives.
Best regards from México.-
Hello Adrian,
I got married in February this year and it feels very good and right 🙂 Nerds like us need great women on our side. Take good care of them and congratulation. Cyprian
Congrats on getting married!
Thank you again for this great tutorial on face recognition!
Have a nice honeymoon.Yinon Bloch
Congratulations Adrian,
I wish you both a happy life together!
I read your blog from time to time and enjoy it a lot, I gain a lot of knowledge and ideas from your posts. thank you very much!
Regarding your comments about improving the accuracy of the identity, I would like to share with you that I also play a lot with the various libraries of facial identification.
I’v tried the code I found in Martin Krasser’s post: http://krasserm.github.io/2018/02/07/deep-face-recognition/
Which is very similar to what you’ve shown in this post. I would like to know if there are any significant differences between the two.
After a lot of poking around and testing I also came to conclusion that the dlib library gives the best results (at least for my needs), but without GPU – we get very slow performance.I wanted to know if you tried to use the facenet library, which uses a vector of 512D, from my experiments it seems to have the same accuracy as nn4 (more or less), but maybe I’m doing something wrong here.
I would appreciate a response from your experience ,
Great appreciation,
Yinon BlochHorelvis
Congratulations Adrian!
But now you will don’t have more free time! 😉
Enjoy with your wife for all life!Hossein
Congratulations
I wish a green life for you.
great ThanksNico
Hi Adrian,
first of all congrats.Regarding the code, I tend to agree with Yinon about the fact that the version that uses dlib seems to work better. In particular this version sometimes finds inexistent faces.
What is your opinion ?
Thanks
NicoNaser
Congratulations Adrian and thank you for good tutorial!
Hugues
Very nice postings, and congratulations on your wedding.
Prateek Xaxa
Thanks for the great contents
Wishing Happy Life Together!
Sinh Huynh
Wishing you and Trisha all the best in your marriage.
Many thanks for your tutorials, they are really great, easy to understand for beginner like me.kus
Congratulations!
brett
Congratulations, wish you both the best! Thank-you for this post,ill be attempting it in the next few days, great tutorials always worth a read.
Guanghui Yang
Congratulations Adrian!
Tran Tuan Vu
September 24, 2018 at 10:41 pm
Hi Adrian,
I have tried on my big dataset (250 persons with ~30 image/person). But when I run recogization scripts, I got very low accuracy? So I think I should not use Linear-SVM for training on the big dataset.-
September 25, 2018 at 11:25 am
Hi Tran, I believe that you need more training data. Thirty images per class isn’t likely enough.
-
Keesh
September 24, 2018 at 11:52 pm
Congrats Adrian and Trisha!
I hope you have a wonderful Honeymoon and life together.Emmanuel Girard
September 25, 2018 at 12:02 am
Félicitations. Nous vous souhaitons du bonheur, de la joie, de l’amour et beaucoup de souvenirs. / Congratulations. We wish you happiness, joy, love and many memories.
Namdev
September 25, 2018 at 12:23 am
Many congratulations, Adrian and Trisha
andreas
Hi Adrian,
Thank you for your tutorial. Could you please point out where non max suppression is solved in this pipeline?
Thanks,
AndreasAbhishek Thanki
Hi Andreas,
There was no non-maxima suppression applied explicitly in the pipeline. Instead, it’s applied by the deep learning based face detector used (which uses a SSD model).
Waheed
Congratulation Adrian. You deserve it! Thanks for all your posts. I really enjoy them
Evgeny
Congratulations Adrian! Thanks for your great post. Wish you a happy life together!
Pardis
Wishing you both a lifetime of love and happiness. And thank you for this great tutorial.
Chunan
Congratulations! Happy wedding.
MD Khan
Congratulations Dr!
siavash
<3
-
Hello Adrian,
Hearty congratulations and best wishes to you and your wife.
Regards,
#0K
Devkar
Congratulations….
Zak Zebrowski
Congrats!
-
September 26, 2018 at 11:08 pm
Congratulations Adrian and Trisha. Wish you a wonderful life ahead.
PFC
If I want to add a person’s face model, do I just need to add that person’s face data set to the dataset folder?
-
Hi Peng — you’ll need a folder of face pictures for each person in the dataset directory. Then you’ll need to extract embeddings for the dataset and continue with the next steps.
noura
how do the extract embedding ?
Arya
Tried that. Still shows uknown
-
wayne
Thanks for your course and congrats!
Thanks Wayne, I’m glad you’re enjoying the course 🙂
Hariprasad
Happy Married Life
Thanks Hariprasad!
-
Thank you, this really helped me …
Thanks Cara, I’m happy the tutorial has helped you 🙂
-
Congratulations Adrian and thanks for the tutorial, this is ver usefull…
Thank you 🙂
Hermy Cruz
Hi Adrian! First of all Congratulations!!
I have a question, how can I run this at startup if it has command line arguments(crontab).
Thank you in advance!!I would suggest creating a shell script that calls your Python script. Then call the shell script from the crontab.
Stephen Fischer
Congratulations to you and Trisha! Many of your readers got a chance to meet both of you at PyImageConf, and you make a great couple! Here’s to many happy years ahead!
One quick suggestion – I had been receiving an error as follows in the sample code:
[INFO] loading face detector…
[INFO] loading face recognizer…
[INFO] starting video stream…
[INFO] elasped time: 8.33
[INFO] approx. FPS: 22.09
FATAL: exception not rethrown
Aborted (core dumped)I’m wondering if this is related to imutils Bug #86? Anyways, I put a sleep command in and it addressed the “waiting producer/stream issue”:
do a bit of cleanup
cv2.destroyAllWindows()
time.sleep(1.0)
vs.stop()Thanks Stephen 🙂 And yes, I believe the error is due to the threading bug.
tommy
Dear Stephen,
How about trying to chage code excution order as below?
vs.stop()
time.sleep(0.5)
cv2.destroyAllWindows()It worked for me.
-
Congratulations, Adrian! 😀
Thank you Luis!
Ravindran
Congratulations Adrian and Trisha! Happy wedding!
Thanks so much Ravindran! 🙂
Francisco Rodriguez
Hello Adrian, excellent post I want to ask you a question if I follow your course pyimagesearch-gurus or buy the most extensive version of ImageNet Bundle. I could have support and the necessary information to start a project of face-recognition at a distance for example more than 8 meters
Hi Francisco, I always do my best to help readers and certainly prioritize customers. I provide the best support I possibly can but do keep in mind that I expect you to put in the hard work, read the books/courses, and run your own experiments. I’m more than happy to keep you going in the right direction but do keep in mind that I cannot do the hard work for you. Keep up the great work! 🙂
-
Thanks Adrian, I know that the effort should be mine, the important thing is to have good bibliography and information, thank you I am very motivated and tis post are of great help especially to developing countries like in which I live
-
Chintan
Congratulations to both of you!!
I want to use this face recognition method in form of a mobile application. Currently I have used https://codelabs.developers.google.com/codelabs/tensorflow-for-poets-2/#0 article for developing mobile application from tensorflow for face detection.
Can you suggest me a direction?
Thanks
Kalicharan
I dont have 30+ pictures for each person, can i use the data augmentation tool to create many pictures of the pictures i have by blur, shifting etc
Yes, but make sure your data augmentation is realistic of how a face would look. For example, don’t use too much shearing or you’ll overly distort the face.
Neleesh
Congratulations Adrian, thank you for the tutorial. I am starting to follow you more regularly. I am amazed with the detail in your blogs. I am just curious how long each of these tutorial takes you to plan and author.
Thanks Neleesh. As far as how long it takes to create each tutorial, it really depends. Some tutorials take less than half a day. Others are larger, on-going projects that can span days to weeks.
Huy Ngo
Hi Adrian.
How to apply this model on my own dataset?
Thank you in advance.This tutorial actually covers how to build your own face recognition system on your own dataset. Just refer to the directory structure I provided and insert your own images.
dadiouf
You both make a lovely couple
Thank you 🙂
Q
Adrian,
Congratulations on your marriage!
Take some time off for your honeymoon and enjoy the best time of your life!Thank you so much! 🙂
Rayomond
Hearty Congratulations! Wish you both the very best
Thanks Rayomond 🙂
dauey
have you liveness detection for face recognition systems?its necessary for face recognition systems.
I do not have any liveliness detection tutorials but I will try to cover the topic in the future.
Nguyen Anh Tuan
Congratulation man
Thank you!
Eric
Hi Adrian, Congratulations on the marriage!
Thank you for all the interesting posts!
I wonder if Adrian or anyone else has actually combined the dlib landmarks with the training described in this post? It seems to require additional steps which are not that easy to infer.
I have successfully created embeddings/encodings from the older posts dlib instructions but when I combine them with this posts training 100% of the faces get recognized as the same face with very high accurace despite my dataset containing several different faces. When I changed up the model I saw that it basically only recognized the first name in the dict that is created and then matches every found face to that name (in one case it even matched a backpack).
I spotted a difference between the dicts that get pickled. The one from this post has a text: dtype=float32 at the end of every array but the dlib dict does not have this text. Maybe this is a problem cause? In any case I can’t spot anything else I could change. But I also don’t know how to change that. (Another small difference is that this post uses embeddings in its code and the previous one calls them encodings).
Also, in the text above, shouldn’t it be proba > T?
Sebastian
I’m also trying to combine those two. Did you manage to get it to work?
Naresh
I was also trying to combine both, Had you done that ?
Please let me know.
Varun
Thanks a lot man
You are welcome, Varun 🙂
Arvand Homer
Hey Adrian, thanks for the tutorial.
We are trying to run the code off an Nvidia Jetson TX2 with a 2.1 mm fisheye lens camera, but the frame rate of our video stream is very low and there is significant lag. Is there any way to resolve these problems?
Best wishes.
Praveen
hi adrian, will this algo is useful for faceliveliness detection..
Thanq
with regards,
praveenNo, face recognition and liveliness detection are two separate subjects. You would need a dedicated liveliness detector.
Somo
Hi Adrian,
First of all thanks for the tutorial.
If I were going to use the dlib’s embedding model, but wanting to change from k-NN to SVM how do I do that.Thanks,
SomoYou would replace use the model from dlib face recognition tutorial instead of the OpenCV face embedder. Just swap out the models and relevant code. Give it a try!
akhil alexander
Hi Andrian, your posts are always inspiring.Congratulations and wishing you a Happy married life… I invite both of you to my state, you should visit Kerala at least once in your lifetime https://www.youtube.com/watch?v=gpTMhLWUZCQ
Thank you Akhil, I really appreciate your kind words 🙂
Zong
hi Adrian,thanks for your tutorial!
I’m trying to replace the resnet caffemodel with squeezenet caffemodel. Simply replace the caffemodel file seems not work. How should I rewrite the code?
PS: Congratulations on your marriage!
Thanks again
ZongHey Zong — which SqueezeNet model are you using? Keep in mind that OpenCV doesn’t support all Caffe models.
M O Leong
Hi Adrian.
Having attempted the 1st few sections of your post (recognize.py), surprisingly, when I run patrack_bateman.jpg it appears to recognise the photo as “adrian”. Did you actually add more photos to your dataset so that “patrick bateman” doesn’t get recognised wrongly?
Yes, I read further down the post that more datasets will eventually lead to much-needed accuracy. But I was just wondering how u got to the part to achieve “patrick bateman’ being ‘unknown’ or unrecognized in your tutorial example. Look forward to your feedback.
Many thanks!
That is quite strange. What version of OpenCV, dlib, and scikit-learn are you using?
Harshpal
Hi Adrian, Thanks for the informative article on Face Recognition. Loved it!!!
I have a question on this. What if, I already have pre-trained model for face recognition (say FaceNet) and on top of it I want to train the same model for a few more faces. Is it possible to retrain the same model by updating the weights file.
Or how can this be done. Please suggest ideas.
Regards,
HarshpalYes. What you are referring to is called “fine-tuning” the model and can be used to take a model trained on one dataset and ideally tune the weights to work on another dataset as well.
Hi, Adrian.
Always thanks for your wonderful article.I have tested your code for a week.
It was working for small dataset(1~2 people face).
But when I increased number of people(upto 10), it looked unstable sometims.1.In my test, sometimes, face naming was too fluctuated, I mean,
real name and other name was switched too frequently.
sometimes it worked a bit stable, but sometimes looked very unstable
or gave wrong face-name.
So as you said before, I added more pictures(more than 30 pieces)
to each person’s directory to increase accuracy.
After that, face naming seemed to get more stable, but there are
still fluctuated output or wrong naming output frequenty.
Is there any method to increase accuracy?- Is there possibility on a relation-formula of between face landmark points to distinguish each face more accurately? ( I tried ti find ,but I still failed.)
Thanks in advance for your advice.
Once you start getting more and more people in your dataset this method will start to fail. Keep in mind that we’re leveraging a pre-trained network here to compute the 128-d facial embeddings. Try instead fine-tuning the network itself on the people you want to recognize to increase accuracy.
2D facial landmarks in some cases can be used for face recognition but realistically they aren’t good for face recognition. The models covered in this post will give you better accuracy.
Vijay
What happend if any person other than the one in data set entered in to the frame….
The person would be marked as “unknown”.
Ankita
Hi Adrian,
Firstly, I would like to Congratulate you on your wedding though it’s pretty late!
I wish to know do you follow any algorithms, kindly mention, if any?I’m not sure what you mean by “follow any algorithms” — could you clarify?
Vijay
“Try instead fine-tuning the network itself on the people you want to recognize to increase accuracy”
Can u plz tell me how to do that ☺️
-
Hi Adrian,
Thanks for the info.
I have 2 questions related to this:First, How would I use an RTSP stream instead of the webcam as input. My rtsp source is in the following format:
rtsp://username:password@IP:port/videoMainI can see this stream in vlc on any computer on my network, so i should be able to use that as the source in your script
Second, instead of viewing the results on my screen, how can I can Output it in a format so I can watch it from another computer. Example, How can I create a stream that I can feed into a vlc server, so I can watch it from another computer on my network.
Thanks for your guidance
Hey Ray — I don’t have any tutorials on how to display or read an RTSP stream on the Pi but I will be covering it in my upcoming Raspberry Pi + computer vision book.
anu
thanks a lot for this page…
how do we include our own pictures into this to recognize?Refer to the “Project structure” section of the tutorial where I describe the directory structure for adding your images. If you need help actually building the face dataset itself, refer to this tutorial.
Teresa DiMeola
Hi Adrian,
You are so kind and generous…you must be an amazing human being. Thank you for this tutorial. I cannot wait to use it (I’m still learning some python basics…so not quite ready yet).
But I do have a general question for you, which is – well – not off topic entirely, but also something which you may not know of the top of your head, but anyway here goes: Can you guess at or estimate at what camera resolution/focal length one would go from being a “resolved image” to a “low resolution image?” Let’s assume for the sake of the question/answer that it is a cooperative subject.
Thanks again, for all you do!
Hi Teresa — each camera will have it’s own specific resolution and focal length so I don’t think there is “one true” resolution that will achieve the best results. The results are entirely dependent on the algorithm and the camera itself.
hendrick
hi adrian. i got this error “File “extract_embeddings.py”, line 62, in
(h, w) = image.shape[:2]
AttributeError: ‘NoneType’ object has no attribute ‘shape’”. This code i ran in ubuntu. But in my Mac everything was fine. I used the same version python and opencv.
Thank youIt’s not an issue with Python and OpenCV, it’s an issue with your input path of images. The path to your input images does not exist on disk. Double-check your images and paths.
Rob
Hendrick, I had the same error but it was a problem with the webcam under Ubuntu. Once I set that up correctly everything worked fine.
Tim
Hi Adrian.
Great job u have done~
Here is my question.
How can I plot the decision boundaries for each class after train_model?The scikit-learn documentation has an excellent example of plotting the decision boundaries from the SVM.
S M Yu
What should I do if the camera recognizes a person who is not being trained, does not appear as ‘unknown’, but appears in the name of another person?
-
Hi Doctor Adrian
Great job
I don’t understand this error ” ValueError: unsupported pickle protocol: 3 ” ?Re-train your face recognition model and serialize it to disk. You are trying to use my pre-trained model and we’re using two different versions of Python, hence the error.
Rico
LabelEncoder seems to be reversing the labels. If you try to print knownNames and le.classes_, the results are reversed. So when you call le.classes_[j], incorrect mapping is done. It seems to be causing misidentification on my datasets.
This happens when the list of images are not sorted. After adding sorting of the list of dataset images, it works without problem.
By the way, linear SVM seems to perform bad with few dataset images per person. Using other classification algorithms such as Naive Bayes are better suited few datasets.
Thank you for sharing your experience, Rico!
Gyho
Is it possible to represent the name in other languages, i.e. Chinese?
Thank you very much!You can use whatever names in whatever languages you wish, provided Python and OpenCV can handle the character set.
Shaun
Dear Adrian,
Many thanks for your tutorials. Step by step following your instruction, I have successfully implemented 7 tutorials on my RPi. The most fun part is this opencv face recognition tutorial. I train the model by adding my family members. It works pretty accurate at most time but sometimes either your name or your wife name pops up. LOL Anyway, your professional tutorial makes me feel like a real coder, though I am actually a dummy :). Wish you and Trisha a Merry Christmas and Happy New Year.
That’s awesome Shaun, I’m so happy to hear you’ve been able to apply the face recognizer to your own projects 🙂
Igor
Adrian. Great job. Please tell me how to write a file to the file? Thank.
I’m not sure what you mean by “write a file to the file”?
Sorry 🙂 Write frame to file.
You can use the “cv2.imwrite” function to write a frame to disk.
Yong Shen
hi Adrian,thanks for your tutorial!
I tried to run this project using opencv 3.3.0 instead of 3.4.2 to avoid lengthy reinstallation… can it work in opencv 3.3.0 ?I would highly recommend you use OpenCV 3.4.2. You can actually install OpenCV via pip and save yourself quite a bit of time.
Tejesh
Happy Married life and thanks once again for such enriching article.
BTW, you had in one of your articles mentioned a link to the zip file containing the General Purpose Faces to be used with the code. Can you please share that link once again over here?
Thanks in Advamce
Thanks Tejesh, although I’m not sure what you mean by the “general purpose faces” — could you elaborate?
-
Hi Adrian,
Thanks for the great tutorial and clear site.
Its a ton of information. I just started this afternoon after searching the web on how to start, and now i have my own small dataset, and the application is running great.My next step is finetuning with Face Alignment, and put more data in my dataset.
Thanks.
Congratulations on already being up and running with your face recognition system, nice job!
Muhammad Salman Ali Khan
Hello Adrian,
I am facing this error when I run train model:
ValueError: The number of classes has to be greater than one; got 1 classIn line 34 => recognizer.fit(data[“embeddings”], labels)
Are you trying to train a face recognizer to recognize just a single person? Keep in mind that you need at least two classes to train a machine learning model. If you’re trying to train a face recognition system with more than 2 classes and you still received that error then you have an issue parsing your image paths and extracting the person name/ID.
Kyle Anderson
What happens if you do want to just train one one person, at least for the time being? I’m trying to create a python script that takes pictures of a person, then trains itself to recognize that person. There may eventually be more than one person, after more people sign up, but for the first user there would only be one person.
Bhanu Jamwal
now the question is how to convert this folder opencv-face-recognition in a api which one can use in web application and websites to have this feature.i will be very thankful if you remove my doubts and lead me a way out of this
thank you
bhanuI demonstrated how to create a REST API for computer vision and deep learning here. You’ll need to modify the code to swap out the Keras code for the OpenCV face recognition code but the framework is there. Good luck!
thank you sir.
you are great
have a nice day.You are welcome!
Mike
Hi Adrian!
Thanks alot for these amazing tutorials, i’ve gained lot’s of interest about the computer vision subject and i’ve been enjoying your deep learning crash course.
I’m doing a class project for my University, which involves face recognition.
One of the requirements of the teacher is the installation of the scikit-learn package.. i’ve noticed that you have used it in this tutorial.
Now, my concern is, my teacher also expressed that people that use PyTorch or TensorFlow will get a better grade in their projects. I’m not familiar with PyTorch but i’ve noticed in this tutorial that you do indeed have a PyTorch implementation, am i right?
In that case, can scikit learning and PyTorch work together? Am i misunderstanding something about this? Also, what possibly could i add in terms of PyTorch usage that could improve this tutorial that you provided (besides the points that you mention in the end of the tutorial (face-aligment, more data, etc) ?
Thank you!
Happy 2019.This tutorial leverages a model trained with PyTorch but it’s not actually a PyTorch tutorial. I personally prefer Keras as my deep learning library of choice. If you’re interested in combining scikit-learn with Keras be sure to take a look at my book, Deep Learning for Computer Vision with Python, which includes chapters using both Keras and scikit-learn.
Best of luck with the project!
I see, so in this tutorial in particular we are indeed using PyTorch and scikit together, correct?
Yes, i’ve asked my teacher about that and he also says Keras wouldve been better but it would also be harder (?), i am indeed very interested in this computer vision subject and your book in particular.. just would like to know if you’re planning to have some sort of discount for students or anything like that because paying 200+ € right now as a student isn’t as easy as it would be in the future 😀
Thanks Andrian!
No, this tutorial is using OpenCV and scikit-learn. The model itself was trained with PyTorch there is no actual PyTorch code being utilized. Instead, we are using a model that has already been trained.
Gaurav
I found This technique is not gives output accurately ..
please can you have a more accurate technique to recognition???How you tried my suggestions in the “Drawbacks, limitations, and how to obtain higher face recognition accuracy” section of the tutorial?
Yes I followed your Suggestions.
I take 70 samples per person.
then also wrong match and not match scenarios happened more times.How many unique people are in your database? 70 samples per person is a good number but I’m curious how many total people are in your dataset?
Adrian
i include 3 peoples in my dataset.
it cannot display accurately names sometime it display right name but sometime it gives the name of another person.For only 3 people the model should be performing better. Have you used the dlib face recognizer as well? Does that model perform any better?
yes i used it
At that point if dlib and the FaceNet model are not achieving good accuracy you may need to consider fine-tuning an existing model. But for only 3 people either dlib or FaceNet should be performing much better. I think there may be a logic error in your code so I would go back and reinvestigate.
Hey Adrian!
How could one implement face alignment on this tutorial?
I can perform face alignment because of your other tutorial but don’t know what i’m supposed to do with the new aligned faces.. would you save them directly in your dataset? If so, how?
Thanks in advance.
Cumps!Take a look at my face alignment tutorial on how to properly align faces. You would want to align them before computing the 128-d face embeddings.
Abdull
Hi Adrian may i ask why do u resize the image in the first place?
High resolution images may look visually appealing to us but they do little to increase the accuracy of computer vision systems. We reduce image size to (1) reduce noise and thereby increase accuracy and (2) ensure our algorithms run faster. The smaller an image is, the less data there is to process and the faster the algorithm will run.
So it’s basicly about the dimension reduction feature of scikit-learn?
We are reducing the dimensions of the image/frame but I’d be careful calling it “dimensionality reduction”. Dimensionality reduction typically refers to a set of algorithms that reduce the dimensionality of an input set of features based on some sort algorithm that maximizes feature importance (PCA is a good example). Here aren’t removing pixels based on “importance”, we’re simply preprocessing the input image by reducing its size.
Philipe Huan
greetings , i have a question, in the file of labels, their content has only a name per person recognized or are there names for represent each image file?
Sorry, I don’t think I understand your question. Could you elaborate?
Dario
Hello Adrian, how we could train a model to recognize rotated faces in different angles??? I want to make facial recognition through a eye fish camera
You normally wouldn’t do that. You would detect the face and then perform face alignment before performing face recognition.
benny
Hi Adrian, if I previously have many images trained using the SVM, and now I have several additional images (correspond to new people), I need to retrain the SVM by scanning through all 128-d vectors. It would take a lot of time when the number of images is kept increasing.
Is there any tricks to improve this scalability issue? Thank you
You are correct, you would need to re-train the SVM from scratch. If you expect that more and more faces will be added I suggest you look at “online learning algorithms”.
Thank you. Apart from the scalability issue, I would like to know the performance of SVM compared with other simple classifier. For example, L1, L2 distance, and cosine similarity. Any comments on this comparison? Thanks
Are you asking me to run the comparison for you? While I’m happy to provide this code to you for free please keep in mind that I’m not going to run a bunch of additional experiments for you. This blog is here for you to learn from, to get value from, and better yourself as a deep learning and computer vision practitioner.
I would highly encourage you to run the experiments and note the results. Let the empirical results guide you.
San Man
Hello Adrian,
Congratulations for your wedding!
Thanks so much for sharing your knowledge, it’s just incredible what you are doing.
I was going through your code. When I ran it, the faces which were there in the model were detected accurately. But the faces which were not there were detected wrongly as some one else.
I had about 10-12 images of each person.
Any idea on how I can reduce the false positives?Thanks,
SandeepSee this tutorial for my suggestions on how to improve your face recognition model.
Hala
hi Adrian,
many thanks for your efforts, i have a question please:
if i have many many images for many faces and i need to group it automatically by unique ids (grouping all faces to the same user in one unique id), how i can do it?
Roberto Marcoccio
Hi, i tried to build my own face normalized dataset applying face alignment you described in the other topic, but that causes to have all 256×256 pixels “aligned” images ….Applying on that the extraction of embedding I noticed something was wrong because not all the images were processed. Debugging finally I got that the face detection of the extraction step of this module applied on the 256×256-sized images obtained cropping the ROI of the alignment step doesn’t work well. To confirm that I also just modified the routine cropping the ROI for each image from the face detection (without performing alignment) and saving it as new dataset and the extraction step just serialized 1 encoding !!!! Summarizing it seems that a further face detection applied on images already “detected” and saved with the dimension of the ROI doesn’t work. If that I don’t know how to apply alignment to normalize my face dataset. Could you pls help ???????????
I’m a bit confused regarding your pipeline. You performed face detection, aligned the faces, and saved the ROI of the face to disk, correct? From there all you need to do is train your model on the aligned ROIs (not the original images).
If only 1 encoding is being computed then you likely have a bug in your code (such as the same filename is being used for each ROI and the files are overwriting each other). You may have a path-related issues as well. Double-check and triple-check your code as it’s likely a logic problem.
Muhammad Hassam
hi Adrian thanks for this amazing post
i wondering if i could use this code on raspberry 3 pi b+ or not ?
i used this https://pyimagesearch.com/2018/06/25/raspberry-pi-face-recognition/ tutorial and this worked fineYes, but the face recognition will be very slow. You may also need to use a Haar cascade instead of a deep learning-based face detector.
Steve
Muhammad, I have a raspberry pi and a camera located where I want to capture images and then the images are sent back to my main PC for processing. There are probably a lot of ways to do it, but this pyimagesearch topic got me on the right path: https://pyimagesearch.com/2019/04/15/live-video-streaming-over-network-with-opencv-and-imagezmq/
Vishal
1)hey Adrian how can i self tuned this code can you guide?
2)and also in this code I not get Unknown Label to any unknown person?
Both of your questions can be address in this tutorial.
How the Self tuning will be done?
can you guide me about it.Ucha Samadashvili
Hello Adrian,
firstly, I am grateful for your work. It has helped me for my Senior Design class project.
I want to ask you a question:
The way machine learning algorithms usually work (from what I understand) is, it gets trained on dataset allowing the algorithm to set weights. When training is done and we want to predict or classify we simply input the new data into a function which already has weights set. Effectively we do not have to compare the new data to all the previous data.
Now, the algorithm for face recognition you described has to look for a face at each frame and then encode it and then compare it to every single encoding in the database. While this is fine for my project since we are only 3 in the group and each has about 50 images in their face directories, it is relatively slow. Yes, I am running the program on a CPU and I understand it can be much faster. However, is there a way of training the machine in such a way that instead of going through each individual encodings (150 in my case) it can go through only 3 where each encoding is going to be some kind of average of one persons face. I know doing the avarage is kind of silly coz of angles and facial expressions etc. but there got to be a way for it work faster.There are a few questions here so let me answer them individually.
Yes, many machine learning algorithms are trained on a set of data, any weights/parameters are set during the training, and the model is serialized to disk. Keep in mind we’re doing the same thing here though with just a few caveats. We have a pre-trained face recognizer that is capable of producing 128-d embeddings. We treat it as a “feature extractor” and then train a model on top of those 128-d embeddings. Think of the face embedder as a feature extractor and you’ll see how it’s just the same method.
You won’t obtain much of a speedup by training from scratch. The model will still need to perform a forward-pass to compute the 128-d embeddings. The only step you’re removing is the Linear SVM which will be pretty fast, regardless.
That said, if you want to train your own custom network refer to the documentation I have provided in the tutorial as well as the comments.
ucha
I don’t think you understood my question. Perhaps, I did not phrase it correctly. Finding a face on each frame is very similar to what other machine learning algorithms do. What I was asking about is comparing the already embedded face to each and every face encoding in the database. To be precise, the efficiency of the voting system is under the question. I was wondering if it is possible to compare the encoded face from frame to some kind of average encoding of each person in the database.
It would be easier to instead perform face alignment, average all faces in the database, and then compute the 128-d embedding for the face.
Neha Jain
Hi Adrian.
Can this library be supported by Python 2.7 and Windows Operating systemTechnically yes, but you’ll need to install dlib on Windows. Please keep in mind that I don’t support Windows here on the PyImageSearch blog. I highly recommend you use a Unix-based OS such as Ubuntu or macOS for computer vision.
Vasya
Hi Adrian!
Thank you so much for your work. Is there a way to add images of new people to an already trained system without running through all already existing images?Yes, you can insert logic in the code to check and see if a face has already been quantified by the model (the file path would serve as a good image ID). If so, skip the image (but still keep the computed 128-d embedding for the face). The actual model will need to be retrained after extracting features.
Huang-Yi Li
If I want to update a new person into our model, whether this model can not be retrained.
Yes, the model will have to be re-trained if you add in a new person.
Pankaj Kumar
Hello Adrian,
can u please tell me why u passing unknown person images, this model itself should recognize unknown person if it not trained on that person….
i want to use SVC only..is their a way to achieve thisThe purpose of the unknown class is exactly that — label people as “unknown” if they are not in the training set. You can use an SVM with a linear kernel to obtain your goal.
kharman
will this post will help to create a project to recognize plants?
No, you should use a different type of machine learning or deep learning than that. If you’re new to the world of computer vision and image processing take a look at Practical Python and OpenCV which includes an introductory chapter on plant classification.
Sari
Why linear svm classifier is better than knn classifier?
Which method is most effective when we have dataset and many faces?Hey Sari — I cover machine learning concepts this tutorial. That post will help address your question.
Mustapha Nakbi
Hi adrian,
I am not satisfied with the SVM trained model, can i define my own deepLearning network(using tensorflow) instead of svm to get better result?Have you tried fine-tuning the existing face embedding model? that would be my primary suggestion.
I am using openface the same embedder model, how to make tuning ,please tell me.
and, is’t possible after extracting the face region i will train the CNN with these regions?
Jaiganesh
Hi Adrain,
I am working for Face recognition feature implementation for Robot to recognize registered office members face. So, in order to recognize face, we can only capture “few pictures (max 5?)” from my office members and i will not able to collect more pictures of each and everyone. With these few samples, we will need to do the face recognition.With this requirement in my hand, i found your previous post (https://pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/) on dlib with face_recogtion library and tested with few of my team member face pictures (“aligned” with https://pyimagesearch.com/2017/05/22/face-alignment-with-opencv-and-python/), but it is not recognizing correctly as expected (identifying as wrong person). May be my team members are chinese and look similar?
So, here i need your advise and suggestion on which one to use?
Should you use this post application (OpenCV Face Recognition)? Or your previous post with dlib? for my above development scenario? Please suggest.And regarding porting train_model.py script on dlib based face recognition application, i have copied recognizer.pickle and le.pickle from this post to other application with dlib on the same output directory. And also modified the train_model.py with “encodings” text to look for encodings.pickle file and ran the train_model.py script. But after this training model script, i see still the face recognition is not so accurate as expected for Robot. Please correct me if i did anything wrong here.
Please guide and help on this. Thank you.
I would try using dlib’s embedding model and then try training a Linear SVM or Logistic Regression model (from this post) on the extracted embeddings. I’ve found dlib’s model to be a bit more accurate.
Johan
which post?
tony
Hi Adrian
Thanks a lot for such an informative post. I have followed the procedure to train my own set of images and recognize. I had put 6 images of a person in the folder dataset > name of the person. My question is if the network cannot work effectively for the new set of images, how does it classify you or trisha for just 6 images ?
It’s not that the network will “never work” with a small image dataset — it’s that larger image datasets are always preferred for higher accuracy and reliability.
Arbaz Pathan
I have done this project, and done it using webcam. Now when the frame window is opening it is giving an fps of 0.34 to 0.40 and it is lagging very much. Due to this we are not getting accurate output. The RAM consumption during this process is 92%. So please do tell us how to resolve this issue. Is this the problem of webcam or raspberry pi?
If you’re trying to perform face face recognition on the Raspberry Pi you should be following this tutorial instead.
Danny
I have to use Deep learning classifiers instead of linear support vector classifier …how it can be done?
Adrian , SVM is not satisfactory … could pls refer me a deep learning model to train on the embeddings…for better accuracy… and if any new face is detected it is not recognizing as unknown…
Hi Danny — you’ll definitely want to read this tutorial where I share my suggestions on obtaining higher face recognition accuracy.
Tara Prasad Tripathy
Hi Adrian,
I was wondering whether the dlib pipeline which you wrote in another post, takes care of face alignment or do we have to incorporate it?No, you need to manually perform face alignment yourself. Refer to this tutorial on face alignment.
fajar yuda pratama
can we train new face without delete last train? for add face data without train all of face again
I have addressed that comment in the comments section a few times, please give the comments a read.
mithil
how to improve the accuracy ??? for me the result is in-accurate. wrong prediction for faces
Kindly take the time to read the tutorial. I cover your question in the “Drawbacks, limitations, and how to obtain higher face recognition accuracy” section.
-
Hi Adrian .. i have project on face recognition but i can not know how to dteremine the percentage of error of algorithms that used in face recognition .and what is the best algorithm for face recognition .Thanx
Victoria
Hey Adrian,
Thank you so much for this guide! My question is, do I need to input the names of the folders into the code where it says “name” or will that assign itself automatically? For example, in lines 47-53, can I leave it as “name” or should I say “adrian = imagePath.split(os.path.sep)[-2]” instead? I’m also having difficulty setting everything up, I’m new to OpenCV but I believe I have version 3.4.7. is this okay or should I get 3.4.2 instead? Thanks in advance!
You don’t have to change the code, just update the names of the directories and the images inside each of the directories.
-
Hi Ardian,
Is it possible when the unknown person is came ,it detects unknown and generating Id for him/her. If again same that unknown person will come,It have to show previous generated Id .
If possible please resolve my issue.Thanks in advance
Zheng Li
Hi, Adrian,
Did you had test the LightenCNN face recognizition model(https://github.com/AlfredXiangWu/face_verification_experiment)? How about it compared to OpenFace,and dlib’s embedding mode?
I have not tested that model, I am not familiar with it.
唐国梁
Thanks a lot . it is really helpful. It worked well.
You’re welcome, I’m glad you found it helpful!
Quek Yao Jing
Hi, Adrian I am a fan of your blog. Your blog had really helped me learn OpenCV a lot. From the previous tutorial, DLIB is used for face detection and k-nearest neighbor is used for a face recognition/classification. While in this tutorial OpenFace is used for face detection and SVM is used for face recognition and classification.
From what I had experience from your code, face detection is more accurate using DLIB while SVM is better in the classification of faces. So, now I am planning on using 128-d embeddings generated from DLIB and use SVM for classification.
My question is if I used this method, will the false positive still occurs if I will need to recognize the 1000-10,000 of people? Because I just wonder how the API like AWS, Microsoft Azure can get really good accuracy despite so many people is using their API.
For 1,000-10,000 people you should really consider fine-tuning the model rather than using the pre-trained model for embeddings. You will likely obtain far better accuracy.
Thanks for your reply Dr Adrian, what does fine-tuning the model means? Does it mean we need to retrain the K-NN or SVM model for the classification process or we need to retrain a custom model for face detection? Because it seems like dlib doing a good job detect face inside the image.
No, fine-tuning the model means taking the existing model weights and re-training it on faces/classes it was not originally trained on. This post covers fine-tuning in the context of object detection — the same applies to face recognition as well.
Thanks Dr Adrian. I will check on your post. I had googled a bit and found out that it seems to be related to Deep Transfer Learning (DTL).
Hamdi Abd
why i get this issue !!
serializing 0 encodings . . .
what i should do !!It sounds like the path to your input directory of images is not correct. Double-check your file paths.
Elijah
Hi, which of the recognition methods is more efficient? This tutorial or the previous?
Marcello Beneventi
Hi Adrian,
Thanks for such awesome blogs and I really learnt many concepts from you. You are kind of my Guru in computer vision.
I needed a little help, I am trying to combine face recognition and object detection both in single unit to preform detection on single video stream. How I am suppose to load 2 different model to process video in single frame? Kindly help.
I would suggest you take a look at Raspberry Pi for Computer Vision where I cover object detection (including video streams) in detail. I’d be happy to help but make sure you read the book to understand the concepts first.
Taka
Thanks Adrian, you’re just a rare being….
I assume that’s a good thing? 😉
Yusuf Yasin
Hey all,
I downloaded the code and made sure all the dependencies and libraries were installed. Unfortunately, whenever i run the code it works for the first couple of seconds identifying faces perfectly, then after a few seconds it causes the PC to crash resulting in a hard reboot.
Has anyone else been facing this problem. If so any help is much appreciated, thanks!
I’ve already posted this once before but it doesn’t seem to appear to be posted.
That’s definitely odd behavior. What are the specs of your PC? And what operating system?
bagas
Hey Adrian, i use 9500 class data train and success, but i running script recognize_video.py very slowly. can help?
quynhnttt
Hi adrian
Can I do this project with IP camera?
thank youdavid
Hi Adrian
Can I do this project with camera IP or camera USBMohamad
Hi Adrian
when i run the code i get this error
AttributeError: ‘NoneType’ object has no attribute ‘shape’
the error located in line 50 image = imutils.resize(image, width=600)
Your path to the input image is correct and the returned image/frame is None. Double-check the path to your input file.
jon
thanks for this awesome tutorial!
would you point me to the right direction on how i can track the learning of this model?thanks again
What do you mean by “track the learning”?
Michael Maher
Hey Mr.Adrian
Thank you so much for all your hard work, sharing with us all this knowledge.
You published many face recognition methods, which one would you consider the most accurate? I am building a project where I want to depend on “face unlock” to unlock/open,
What is the best method suitable for this in your opinion?
Thanks.
It depends on the project but I like using the dlib face recognition embeddings and then training a SVM or Logistic Regression model on top of the embeddings.
kayle
great work !! this program can recognise only human faces no ? cause i am wondering if i can use it to recognise my plants on real streaming time is it possible to do that just by giving pictures of my plants ? if its not the case can you give the path of a program that can do that please
No, this method is used only for face recognition.
For plant recognition I would recommend either Deep Learning for Computer Vision with Python or the PyImageSearch Gurus course (both of which cover plant recognition).
I hope that helps!
Abay
Adrian, thank you for such a great article!
I tried to use my own trained model on PyTorch and exported into ONNX. However when I try to read it with OpenCV I get errors. I found that overall people have problems with importing deep learning models into cv.dnn (Keras, PyTorch(Onnx), etc).
So my question is: isn’t it better to have a separate microservice (e,g. flask + PyTorch) which will serve requests coming from an app which probably uses OpenCV to send image/images(in case of video stream). How such architecture will differ in terms of speed compared to the case when open cv uses a pretrained model as you showed above.
The OpenCV, PyTorch, Keras, TensorFlow, ONNX, etc. ecosystem has a long way to go. It’s a good initiative but it can be a real pain to convert your models.
You can technically use a microservice but that increases overhead due to HTTP requests, latency, etc.
Pyro
Hello Adrian, when i download and use your trains and code without changing anything with adrian.jpg. There are a lot of squares in your face and all like %50 adrian. There are like 7-8 squares (adrians). I gave it a try with my photos, added like 40 photos, removed outputs.
First i used extract_embeddings.py, then i trained it with the script and i tried to recognize and result is same. There are like 7-8 squares in my face and all are %40-50.
Help me please :/
The fact that there are multiple face detections which is the root of the issue. What version of OpenCV are you using?
Hello Adrian, i use OpenCV 4.0. i took a look at your https://pyimagesearch.com/2015/02/16/faster-non-maximum-suppression-python/ but i couldn’t figure how to use both together.
I would suggest taking a step back. Start with a fresh project and apply just face detection and see if you are able to replicate the error.
Khoa
Hello,
I ran your code successfully. However, in some cases, I want to filter the images with lower confidence. For example, the code recognizes two people as me with the confidence 98.05% and 92.90%. How can I filter the ones below 95% ?
All you need is an “if” statement. Check the confidence and throw out the ones that are < 95%.
kumar sahir
Dear adrian,
first thank you for your excellent tutorial it is very helpful, I am PhD student in computer science, I saw your tutorial about facial recognition, I was very interested in your solution, and i want to know if it is possible to make the search on web application (From web Navigator) instead of using shell commande, thnak you very muchCordially
Yes, absolutely. I would recommend you wrap the project in a REST API. This tutorial would likely be a good start for you.
sizbro
Hey Adrian, I know its been a while since you answered a question on this post, but I have one lingering curiosity. I have been trying to add members of my own family to the dataset so it can recognize them. Right now I have been having an issue with the labels as it still shows either ‘Adrian’ or ‘Trisha.’ Do you know how I can edit the labels so that the names of my family are there instead?
I’m not sure what you mean by it’s been “awhile”. I regularly comment and help readers out on this post on a weekly basis. You should take a look at the recent comments before making such a statement 😉
As for adding family members you need to:
Delete the “Adrian” and “Trisha” directories and add in your respective family members
Extract the facial embeddings from your dataset
Train the model
From there your family members names will show up.
Mudassir Ahmed Khan
What are command line arguments and their parsing?
You can read about command line arguments in this tutorial.
Khang
How do I apply facial landmarks on this tutorial to increase accuracy of recognition?
You can use them to perform face alignment.
Rajath Bharadwaj
I was wondering how to recognize multiple faces. Could you give me some leads on that? That’d be great and very helpful.
And thank-you for all your great tutorials and codes. Really, it’s helped me a lot!
Thanks once again.This method does work with multiple faces so perhaps I’m not understanding your question?
Jose Fierro
Congrats!!, Great tutorial Master.
I just have a question, each time you add a new person, do need to train again the SVM or exists another way?
Thanks
If you add a new person you will need to retrain the SVM.
Amos Cheung
Hi! First of all thanks for the tutorial. I just have one question. Is there anyway to construct the code so that all new faces will be recognized as “unknown” rather than having to add data in there. Thanks
It will already do this. Each image gets converted into an embedding (a bunch of numbers). Each person will have a pattern to their embeddings. If you have enough images, the SVM will pick up on those patterns. Since the “unknown” folder has a ton of random images in it, those embeddings will be all over the place — it won’t have an easy to model pattern. So it should learn, on its own, that if a face is “weird” it should be labelled unknown.
-
Hi adrian!! I am a big fan of your work and although it is too late i wish you a happy married life.I was wondering , can we combine your open cv with face recognition tutorial(this tutorial) with the pan-tilt motor based face recognition tutorial and enhance the fps with movidius ncs2 tutorial(on raspberry pi) to make a really fast people identification raspberry pi system which can then be utilized for further projects.I just wanted to know whether it can be done or not and if it can be done, how should i go ahead with it ?I have already applied and made these projects separately in different virtual environments, now i need to somehow integrate it.Thanks for your help in advance.
Bruce Young
Thanks for your great tutorials. 🙂
I had an error while training that several others have had.
“AttributeError: ‘NoneType’ object has no attribute ‘shape’”
My path to the training images folder(s) was fine.
For my case at least, the issue was that I am doing the tutorials on a Linux machine but I collected the images using my Mac and then copied the folders across the network to the Linux machine. That process copies both the resource and data forks of the image files on the Mac as well as the Mac .ds_store file. Many of these files are hidden. Once I made fresh dataset image folders and copied the training images into them using the Linux machine, all was good.
Thanks for sharing, Bruce!
Fouk
how to use face-recognition with gpio in raspi
That exact question is covered inside Raspberry Pi for Computer Vision.
Laxmi Kant
Hi Adrian,
Thank you so much for developing it quick and easy stuff with OpenCV.
I am using it on Windows-10 machine, it worked great.
Thank you once again for creating it.
laxThanks Laxmi!
john
Hi, Andrian!
U can help me to assign the picamera to on Jetson Nano for videostream face recognition?
The real issue is that I can install “picamera[array]” on my Jetson board.Thanks!
Ajmal
Hello Adrian! Thanks a lot for these tutorials. Your tutorials have been my first intro to Computer Vision and I have fallen in love with the subject! I’m on my way to do my M.Sc. with a focus in computer vision now, and it all started from your tutorials! 😀
I’m aware this may not be the right place for this question, but wanted to know your take on it regardless:
How well does SVM scale? I tried to do a test with dummy vectors, and the training time seems to scale exponentially. Have you had any experiences in scaling this for large datasets (in the order of tens of thousands of classes perhaps)?
Also, what is your opinion on using Neural Networks for the classification of the embeddings as opposed to k-nn (perhaps with LSH) or SVM for scalability?
Any tips/information or links to resources would help me a lot! Thank you once again for these wonderful tutorials!
Pankaj
Hey Adrian. Thank you for this amazing tutorial. Loved it. I’m working on a project where I’m supposed to recognize the faces of the moving people. Like people approaching my front door or maybe people in a locality , given I have the dataset of that locality. I’m supposed to identify unknown person accurately for safety purposes. Can you please help me on this. How can I use this tutorial in doing that .
That exact project is covered inside Raspberry Pi for Computer Vision. I suggest you start there.
Nick Kim
Hi Adrian,
Great post as usual but wondering why SVM is used for classifying rather than a fully connected neural network with softmax activation?
Thanks,
Nick
September 12, 2019 at 11:42 am
You could create your own separate FC network but it would require more work and additional parameter tuning. It’s easier and more efficient to just use a SVM in this case.
Shashi Kiran
Hi Adrian, Thanks for sharing such wonderful blogs on OpenCV, DL. Very useful, informative, educational and well presented in layman terms. I have learnt a few things so far thru your articles.
My question : Let’s say I have trained my engine with 20 or more images and some images were not well interpreted by the engine. How would I know that ?
Is there someway the engine will try to digest it and throw it out with some result that says image is 90% good, or 10% good/bad.( It could be image is blurred, image where the eyes are closed, streaks in images, rotation was not aligned and engine could not process, and other things that you mentioned in the “Drawbacks” section of your article – things like that )
These lead to bad probability which I can avoid by creating a second set of well crafted images.Was hoping to hear your opinion on it.
I have about 40 images of a single person and yet I get 20 or 30% probability and sometimes wrong names during recognition !! so I am thinking my set is no good – but which image is bad in my set ? I need to be able to identify that so that I can train my engine with a better set of photos.Again thanks for wonderful articles.
John
Hi Adrian, thanks for the tutorial. I have a question about processing speed. Is there any way that the forward() function speed can be improved or why does this take the most time? When running this on a Raspberry Pi, it seems to be the bottleneck of the recognition. Makes things especially harder when trying to recognize faces in frames from a live video stream.
September 19, 2019 at 10:06 am
Hey John — take a look at Raspberry Pi for Computer Vision where I show you how to perform face recognition in real-time on the RPi.
-
I also have a question similar to this. And thanks Adrian for the answer.
Abhishek Gupte
Hey Adrian,
I’m facing a rather weird problem. When I train one of my friend’s face BUT NOT MINE, the program still recognizes my face as my friend’s with an above 50% probability but when I train BOTH OUR FACES, it recognizes my face correctly as an almost equal probability as in the former case. What seems to be the problem?
P.S I also tried experimenting with different values of C but to no avail.Joe
Hi Adrian,
Can this work with greyscale images? I.e. can cv2.dnn.blobFromImage still be used with non RGB images. Asking this because I want the recognition to not be dependent on lighting (if lighting actually even affects this)
Just stack your grayscale image to form an RGB image representation:
image = np.dstack([gray] * 3)
Hey Adrian,
First of all great post, now since you reply to so many people, I won’t take much of your time.
I have just one question. Can an image size(resolution, size on disk) disparity between dataset and camera feed or between images in the dataset make a difference to the probability? I get varying like 20% difference whenever I run the webcam-recognizer script at different times, with the same trained face under same light conditions. With stranger faces it varies just as much and so i can’t set an exact threshold of probability. Some of the sizes on disk for the images is 5 Kb whereas some 200 Kb. Also the images coming from the feed each equal 70kb. Please comment as it’s causing the greatest hindrance. So close I am to building a face recognition system yet this gnawing problem.The image size on disk doesn’t matter but the image resolution does matter. If your image is too small there won’t be enough information to accurately recognize the face. If the image is too large then there will be too many fine-grained details and it could potentially “confuse” your model. Typically input face recognition resolutions are in the 64×64 to 224×224 pixel range.
Abhishek Gupte
What is basically the difference between the resolutions of your camera feed and dataset(the one containing pics of you and your wife and the unknowns)?
Harshit
Just One Question——
Why did we make a blob of the face first, could’nt we directly pass the image to the embedder after resizing it to fit the input_size of the first layer to the embedder.
Is it necessary to make the blob??
OpenCV requires that we create the blobs when using models loaded using OpenCV’s “dnn” model. We need to blobs in this example:
- One blob when performing face detection
- We then create separate blobs for each detected face
manideep
Thank you so much bro
You are welcome!
Hi Adrian,
I am looking to improve the method and am starting with preprocessing of images, specifically face alignment. If face alignment is used to preprocess the images, is there an effect on classifying test images if the face in the image is not completely horizontal (i.e. the eyes lie in the same y-coordinates)?
It can effect the accuracy of the faces are not aligned. They don’t need to be perfectly aligned, but the more aligned they are, the better.
My question may have been unclear. If the training data is aligned, but the face in the test image is not aligned, is that an issue?
The embedding models tend to be pretty robust so it’s not the “end of the world” but if you’re aligning the training data you should also try to align the testing data.
Hello,
For the unknown dataset, is it better to have many pictures of a few people (say 6 different people with 10 pictures each) or as many random people as possible (say 60 different people rather than 6 sets of 10 pictures per person)?
That really depends on your application. I prefer to have examples of many different people but if you know for a fact there are people you are not interested in recognizing (perhaps coworkers in a work place) then you should consider gathering examples of just those people.
Tien
Hi Adrian,
Thanks for your tutorial, it helps me so much to start learning deep learning and face recognition. From this tutorial, i try to improve accuracy by using dlib’s embedding model but have a low accuracy. So i just want to ask one question that if i extract embeddings by using dlib and face_recognition with my dataset, i will use dlib and face_recognition again in step #3 to extract embeddings instead of the model used in this tutorial. It’s right?Yes, you must use the same face embedding model that was used to extract embeddings from your training data.
Safi
Hi Adrian,
I’ve a questions if you have ever had times to wrote a tutorial about detecting faces using IP camera.
I’m working on something to detect multiple faces & gender using IP camera (rtsp).if you do have this tutorial please share the link with down below. thanks I really appreciate your effort.
If I put a ton of unknown images in the unknown folder, it starts predicting that everyone is unknown. I can fix this by either remove unknowns or by just copy/pasting all the images in my other folders so they’re roughly equal (or having it copy the embeddings multiple times for the same effect). Any thoughts on which is better?
Yusra Shaikh
Hi Adrian
This tutorial worked perfectly! i was amazed at how easy it was. All thanks to your detailed explanation. I wanted to extend this project to detect intruders, and raise an alert via SMS. Can you help me just a general overview of how this can be done?
Take a look at Raspberry Pi for Computer Vision which covers that exact project — detecting intruders and sending an SMS alert.
Will
Hi Adrian, thank you for the amazing tutorial.
I have a question and I would like to hear your oppion.
Do you think the reason of the “unknown” prediction when you was wearing a sunglasses is because OpenFace use eye-aligned for preprocessing the input image, so when we wear sunglasses OpenFace cannot align our face correctly that result in low accuracy?
What I mean hear is that although we add more data of people wearing sunglasses in the dataset, maybe the accuracy would not be improved because the OpenFace algorithm cannot perform eye-aligned.
If yes, how would you overcome this problem?
Again, thank you for the nice post. Have a nice day
Meg
Hiii. Does this project detect faces in real time?
Yes, it certainly does.
AKBAR HIDAYATULOH
hi, thanks for the great tutorials. I want to ask, how can i capture face recognition only one time for detected faces as long as the faces are inside the frame, so the captured faces are not every frame, can you give some advice. thanks
Try using basic centroid tracking. Each bounding box will have a unique ID that you can use to keep track of each face.
Aonty
How can I use it for attendance system
I would suggest you read Raspberry Pi for Computer Vision which covers how to build a custom attendance system.
Aadit
Hello Adrian,
Can we use this code in rasberry pi to implement face recognition?If you want to perform face recognition on the RPi, read this tutorial or my book, Raspberry Pi for Computer Vision.
Vinit Shetye
Hey Adrian. Thank you for this amazing tutorial. Loved it. I’m working on a project where I’m supposed to recognize the helmet when riders ride the bike. if helmet not recognize then kill switch off bike not working
I would recommend using a deep learning-based object detector for that, such as Faster R-CNN, SSD, or RetinaNet. You can use those models to detect the helmet. I cover them inside Deep Learning for Computer Vision with Python.
Martin
Hi Adrian
is it possible to use a Siamese network to recognize the face?Yes, absolutely. I would suggest you read up on siamese networks, triplet loss, and one-shot learning.
-
thankyou so much, you are like hero to me.
Thank you for the kind words.
Sanju
Hi Adrian,
What if we want to include the images which belong to some other person apart from the faces present in the dataset ? Do we have to train the model again to recognize that newly added face??
someone
This might be too broad of a question, but: how do I improve the rejection rate of unknown faces?
I currently have two faces trained, but, running some video data, other persons come very close to my comfort limit.
I have about 30-80 pictures trained for each face, but not aligned, in various lighting environments. They are pretty low res, trained from the same camera that does the recognition (~640-720p).Perhaps over-training raises the risk of false positives? Should different lighting be trained with a different label? (e.g. IR vs daylight)
Should unknown persons be put into a different folder? Into several different folders? Currently I have no such folder in my training set, just the faces I want to detect.
If you have enough training data you may want to consider training a siamese network with triplet loss — doing so would likely improve the face recognition accuracy.
Satyam
Sir where and how to change the hyperparameters i.e; C value as mentioned in ur post to improve the system.
sinem
Hi Adrian 🙂
How can I use Python and OpenCV to find facial similarity?I’ve successfully used OpenCV and Python to extract faces from multiple photographs using Haar Cascades.
I now have a directory of images, all of which are faces of different people.
What I’d like to do is take a sample image, and then see which face it most looks like.
Yes, but I would recommend you follow this guide on face recognition. Extract the 128-d feature vector for each face and then compute the Euclidean distance between the faces. Faces with smaller distances are considered “more similar”.
Thank you very much Adrian. Can I do it using the LBPH algorithm, which is the facial recognition algorithm included in OpenCv?
Yes, but your accuracy won’t be as good as using the deep learning-based face recognition methods covered here.
sepideh
Hi Adrian
Thank you very much for your complete code and description.
I wondering to khow , how many face can recognize by this code?
and store how many person identity?
is this good for a university recognition system?
I would be very happy if you could introduce a code or article that could recognition many faces (for university or big company)Phil
For those who are using sklearn v.0.22, there was a change in the library recently that yields the error: AttributeError: ‘SVC’ object has no attribute ‘_n_support’
An explanation is found here:
https://github.com/scikit-learn/scikit-learn/issues/15902To fix the error, you can either revert to <0.22 or retrain the model and then run the recognize[_video].py
Thanks for sharing, Phil!
Venkat Mukthineni
Hey Adrian! Great job
I would like to know how to extract the bounding boxes of recognized or unrecognized face from video stream/ image. I want the face in bounding box to get saved in a folder. I would like to extend the project with google reverse image search (on unrecognized faces)
Thank you
That’s absolutely possible, but I get the impression that you may be trying to “run before you walk”. Take the time to learn the basics of OpenCV first, including the “cv2.imwrite” function and basic NumPy array slicing/cropping. Practical Python and OpenCV will help you with just that.
Ayoub
Hello Adrian , please how can i create an embeddings.pickle and le.pickle for my dataset , thanks !
Follow the steps in this tutorial as I show you how to run the Python scripts used to generate those files.
Yasser
HI…
Are the openface and face_recognition different models? or they work together?
I am confused between them-
Thank you Adrian, this really helped me. Always success ..
Thanks Kaldu!
Barry McQuain
Hi,
Great Post!! Everything works as planned, but I have a few questions:
I get slightly different percentages compared to your demo (ie, 51.03% v 47.09%). It still works, but my results are not exactly identical using the zipped data and code with no changes. Any idea why that might be? It’s not a big deal, just curious.
I added my seven family members, 12 pictures of each, plus another 10 or so random unknowns to dataset to train and a few of each as the images to test. My results are about 50/50 in terms of identifying the correct person.
When it correctly identifies a person, the highest percentage I see is about 35%, and whether correct or not, I see all of my results in the 15% to 35% range. Is this to be expected? Without my new data, the original tutorial of just you and your wife seemed to give results more in the 40% to 60% range.
After adding the new dataset pics above, I do step #1 to extract the 128D data. Then step #2 to retrain. The retraining appears to happen almost instantly, takes less than 1 second. Is it really re-training? I would have expected the retraining to take longer?
You refer to a process whereby I can “retrain” or “fine-tune” – can you give a little more detail about how I can do that? I would like to create a sample of 30 people in my dataset and retrain on just those 30 (with of course a few random ones too). Is this possible?
I left the original pics of you and your wife in my dataset when I added my seven family members. But now, it doesn’t recognize you (adrian.jpg now only gives me a 17.29% and tells me you are now unknown).
I am a high school teacher, and I would like to show my class these results (and I believe a few are ready to learn this themselves.) I have 30 students. Approx how many training pictures of each do you think I will need? Per the above at the present time, I am only 50% correct in identifying the correct person given a dataset of 10 unique people with 12 pics of each.
That isn’t high enough for me to show them. Do you think it is possible, using this tutorial example, that I could get something closer to 95% correct identification of those 30 students (or in my test above, closer to 95% correct identification of my seven family members?
Thanks v much!!
B
Hey Barry, I’m happy to help, but as I’ve mentioned on my FAQs page, kindly keep your comments to one question at a time. I receive 250+ emails per day and 100s of blog post comments. I try my best to get to them all, but multipart questions, especially seven of them, isn’t something I can do. If you want more detailed help kindly become a customer first and then I can help with these longer questions. I hope you understand that I’m trying to “do the most good” and get to as many people as possible, but I can’t possibly get to everyone with these types of comments.
Feel free to pick one of the above questions you want me to answer though.
Thabang
Hi Adrian. Great tutorial. “deeply” enjoyed it. Thanks.
Is it possible to adapt the code to say; If the person in the frame is recognised then they have access to a room? How can i go about to do that?
I would suggest looking into “smart locks”. Some have APIs that you can integrate with and could then “unlock” when a face is recognized.
erol
hi adrian
I am doing a face recognition project with raspberry pi for my school project. The door will be unlocked as the face recognition status. I need to transfer the image taken from the camera to the computer and open and lock the door upon request. How can I make this connectionI suggest using ImageZMQ.
Jestin
Hi Adrian,
Firstly, thanks for all the amazing content!
I’d like to understand if there is any specific reason for using OpenCV’s face detector instead of dlib’s?
I’m curious since you have used dlib’s face detector in your other blog on training a custom dlib shape predictor.Nel
Thanks for the article Adrian,
I am working on a project about face recognition in an uncontrolled environment. So, I need a model to detect unknown person, who I don’t have any pictures of in the dataset. I mean, their picture isn’t even in the unknow folder and my model should label them “unknown”. How should I do that?
Thanks
Talpe Loyange
Have you used both machine language and deep learning for this project and for what ?Can you explain about that
















Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.